As emphasized throughout this series, one of the most significant advantages of the actor model abstraction is its inherent decoupling of agents from threads. This separation allows us to configure the binding of agents to threads using dispatchers, an essential decision that typically depends on the specific requirements of the scenario we’re addressing. This flexibility enables us to dynamically adjust the threading setup, even at runtime, without being tethered to the implementation details of the agents.
However, without clear guidelines or established patterns to follow, choosing the appropriate dispatchers can be a non-trivial decision. It seems Ronnie, a new member of our team, is encountering just this dilemma.
In this post, we would like to share a way to let dispatchers “emerge” from the system: suppose we bind all agents to the same thread leveraging the default one_thread dispatcher. Then we wonder for which agents this decision does not fit, why, and what alternative options are preferable. In this manner, like a sculptor removing material pieces to attain the desired form, we will selectively unbind agents from the shared thread, assigning to other dispatchers only those that would benefit from an alternative strategy.
The aim of this article is to highlight the importance of asking the right questions rather than seeking exact answers. This is because, as mentioned, the process of binding agents to dispatchers is heavily contingent upon the specific requirements of the system. These questions delve into various “dimensions” to consider when determining whether an agent should remain in the shared thread or if it’s more advantageous to bind it to another dispatcher. By understanding the pertinent questions to ask, we can facilitate the emergence of the optimal choice within the system.
Before diving into one of the longest posts of the series, we’d like to provide a concise list of considerations that we’ll explore further in this article. This quick reference guide will assist you in selecting dispatchers for your future projects.
Start by binding all agents to the same default dispatcher. Then, consider the following steps:
- identify agents that require a dedicated thread, either because they cannot be blocked by others or because they cannot block others;
- identify tasks that would benefit from parallelization, both CPU-bound and I/O-bound, and consider distributing them across multiple agents or a single agent with thread-safe handlers;
- identify sequential pipelines and consider assigning all agents involved to the same thread;
- determine if certain agents have higher priority in message handling;
- consider any special context requirements for agents, such as executing logic on a specific or fixed thread;
- for agents that can’t avoid sharing state, consider binding them to the same thread to avoid concurrency issues.
Single-threaded, when possible
When utilizing SObjectizer for the first time, we get exposed to its default dispatcher, known as one_thread, which assigns every agent to the same thread. While this dispatcher may appear trivial, our benchmark discussions have revealed that, put simply, inter-thread message exchange and context switching incur a cost. Practically speaking, if multiple agents have no benefit from concurrent execution, binding them all to the same thread is a valuable approach.
For example, in calico the data production depends on the frame rate of the device. With my laptop hosting a 30fps camera, this translates to approximately 33 milliseconds between two consecutive frames. Suppose we have this setup:
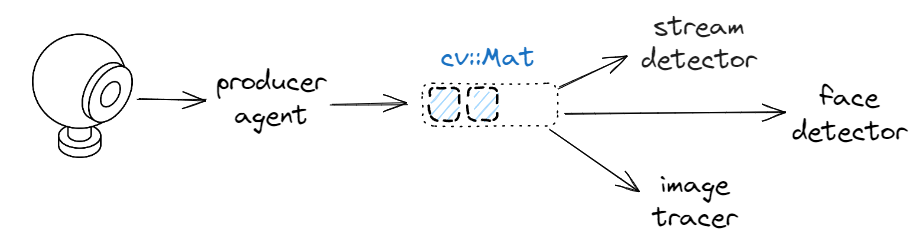
If stream_detector, image_tracer and face_detector process a single frame sequentially and the total time taken remains within 33 milliseconds on average, we could consider assigning them all to the same thread to guarantee a 30fps throughput. This will be equivalent to processing sequentially each frame by the individual agents.
While this observation may appear obvious, it highlights a first guideline: when binding agents to multiple threads is unnecessary or has negative consequences, opting for a single thread is a choice to consider.
Hence, if the aforementioned scenario remains unchanged, opting for a single thread could be a good choice. However, in software development, scenarios rarely remain static. For instance, we may eventually use a new camera that is 100 times faster than our current one, or we might introduce and combine other agents we have developed so far, such as the image_viewer or the image_saver.
Is a single thread still a good choice?
As we delve deeper into the complexities ahead, we’ll explore other dimensions to consider that we’ll discuss in the rest of the article. Speaking in general, there are some common traits that make agents good candidates to share their thread, such as:
- “cheap” operations (e.g. message rerouting);
- agents tolerant of delays in their reactions.
Here are some possible ideas applied to calico:
error_logger(tolerant of delays)image_tracer(tolerant of delays)fps_estimator(cheap operation)maint_guiagents (only reroute messages)stream_detector(cheap operation)stream_heartbeat(cheap operation)
We assume, in this context, that writing to the console is a cheap operation, otherwise, we might introduce an agent solely responsible for console output. In addition, agents that are part of a “processing pipeline” (such as the “pipes and filters” and “routing slip” patterns we encountered in a previous post) are also good candidates. In fact, in the case of pipelines, the decision to employ individual agents (or groups) to operate simultaneously depends on its true effectiveness.
To block, or not to block
We now embark on exploring the first “dimension” to consider to determine whether certain agents should have on their own thread or not.
Let’s get back to the previously discussed scenario where all the agents share the same thread:
What about the producer agent?
In calico, we developed four image producers:
image_producerimage_producer_callbackimage_producer_recursivevirtual_image_producer
Before discussing a possible answer, let’s first examine whether the “traits” for binding agents to the same thread discussed before align with our producers:
- agents performing very “cheap” operations: only
image_producer_callback; - agents tolerant of delays in their reactions: none, in general.
Assuming that starting the camera is a “cheap” operation (it is not, in general, but consider that it’s a mandatory operation we would await in any case to produce data), it seems that only image_producer_callback is a good candidate for sharing its thread with the other agents. Now, let’s get into the things.
To answer the question, we might consider the type of operations the producers perform, which might be either blocking or non-blocking.
Typically, we prefer employing non-blocking operations since these do not cause us to wait for the underlying operation to complete, and also offer the operating system the opportunity to utilize threads more efficiently. These operations include, for example, non-blocking I/O primitives, asynchronous function calls, and operations that use callbacks or futures for handling completion. Non-blocking functions are not black magic and sometimes require support from the operating system.
Waiting inevitably occurs somewhere in the system, but typically, we’re not directly exposed to it. For instance, consider image_producer_callback which does not wait for the next image to be retrieved from the device. Instead, a callback is automatically invoked by the underlying device when the next frame is ready. In this scenario, the producer does not engage in a blocking operation.
On the other hand, blocking operations – unsurprisingly – blocks until a certain resource becomes available – such as disk, network or synchronization primitives. Consider image_producer_recursive and virtual_image_producer: both of these agents perform a “blocking” operation every time they attempt to retrieve the next frame. Even worse, image_producer monopolizes its worker thread by executing a tight loop where the next frame is read on each iteration.
The primary consequence of an agent engaged in blocking operations is clear: if its thread is shared with others, they will be indirectly affected by the blocking operation. Therefore, if it’s imperative that such agents aren’t “blocked”, they should not share their thread with the blocking agent. To address this issue, usually we give the blocking agent a dedicated thread. Also, the opposite scenario is similar: if a certain agent mustn’t be blocked by others, it should have its own thread.
Then it seems we have a guideline: when an agent must not be disturbed by others, or when others should not be disturbed by the agent, opting for a dedicated thread could be a viable solution. Some good questions to ask are: “is it sustainable for the agent to be blocked?” or “is it sustainable that the agent blocks others?”.
While active_obj presents the most straightforward choice, a carefully adjusted thread pool is also a possible alternative. This choice depends on various factors, including the expected number of agents. For instance, in calico there are only a few dozen agents. Therefore, allocating a dedicated thread for each of them should be sustainable, considering also they don’t stress the CPU. However, as we discussed in a previous episode, having a large number of threads could swiftly jeopardize the system’s performance. Take, for example, a massively parallel web server scenario, where allocating a thread for each client, despite potentially involving blocking network operations, might be a risky choice. In such cases, employing a thread pool is typically the preferred alternative. We’ll elaborate this aspect a bit more in another section of this article.
It’s worth noting that while a blocking operation typically doesn’t directly relate to CPU usage, if multiple CPU-intensive operations are simultaneously running and some threads become “blocked” while awaiting their turn to execute instructions, we may also consider this a form of blocking.
To answer the initial question, we should determine which producers are allowed to “block” others and vice versa. A rough answer might be given as follows:
image_producermonopolizes its context then it wouldn’t leave others to handle any events. Thus, it must have its own thread;image_producer_callbackactually uses its thread only in response to start and stop signals (as the callback is invoked on the device’s worker thread). This means, it might share its thread with the other three agents involved in the system;image_producer_recursiveandvirtual_image_producerblock only when handling thegrab_image signal.
It’s essential to emphasize the first point: if an agent monopolizes its context (e.g., if so_evt_start() contains an infinite loop), binding it to a dedicated thread is the only choice. Generally speaking, we say the agent does not work cooperatively as it never gets back control until deregistered. This stands as a general rule.
The last two producers warrant further discussion: while it may seem they should have their own thread, this decision hinges on the broader context of the system. As mentioned earlier, if the other agents operate within the expected throughput, allocating an additional thread for the producer may be unnecessary. Hence, the decision depends on factors such as the arrival rate of images, the impact of operations performed by the agents in the group, and the expected throughput. The advantage is that we have options and can fine-tune the system accordingly.
Finally, we discuss a potential issue with binding image_producer_callback to the same thread as other agents. As mentioned, we consider starting the camera as “cheap” because without starting the camera, the system is rendered useless. This is not true in general. Nonetheless, the crux of the matter lies elsewhere: in practice, after starting the acquisition, image_producer_callback only needs to handle the “stop acquisition” signal to halt the device. Suppose some of the agents experience some delay, leading to an event queue that looks like:

If a stop signal arrives, it will be enqueued at the end as a demand for image_producer_callback. This means, it will be processed after the other 6 demands currently in the queue. Maybe this is not an issue but in some cases it might be. At this point, another feature of SObjectizer is to consider: agent priorities. Essentially, this feature allows for the demands to be handled in different orders based on the priorities of agents. In this context, if we assign image_producer_callback a higher priority than others, the “stop signal” would be processed before the rest of the requests.
While assigning an agent a dedicated thread is the only means to prevent it from blocking others – and vice versa, the notion of “priority” presents another opportunity that can help us in avoiding dedicated threads when they’re not strictly necessary.
In the next section, we’ll learn more about this dimension to consider.
Priority-based considerations
The example presented above is not an isolated case. There are scenarios where multiple agents can share a thread as long as their “priority” influences the order of processing demands in the queue. In essence, every agent can be optionally marked with a certain priority:
class my_agent : public so_5::agent_t
{
public :
my_agent(context_t ctx)
: so_5::agent_t( ctx + so_5::priority_t::p3 )
// ...
};
Priorities are enumerations of type priority_t and span from p0 (the lowest) to p7 (the highest). By default, an agent has the lowest priority (p0). In general, the priority is an implementation detail of the agent. SObjectizer provides three dispatchers that take priorities into account when processing demands:
prio_one_thread::strictly_orderedprio_one_thread::quote_round_robinprio_dedicated_threads::one_per_prio
The distinction between the “one thread” and “dedicated thread” concepts essentially boils down to the following: in the former scenario, where all events are processed on the same shared thread, the dispatcher can strictly order the demands based on the higher priority of agents. Conversely, in the latter scenario, one distinct thread is allocated for each priority.
This feature offers another perspective to determine how to bind agents to dispatchers and offers the opportunity to fine-tune the system based on the relative importance of agents or to partition the binding of agents to threads according to priority.
As mentioned before, for instance, we could consider assigning a higher priority to image_producer_callback compared to the other agents in the group. Then we can bind them all to a strictly_ordered dispatcher that operates intuitively: it manages only one shared thread and its event queue functions like a priority queue, ensuring that events directed to higher priority agents (the producer) are processed ahead of those directed to lower priority agents (image_tracer and face_detector). This way, if the stop signal arrives while the event queue already contains other demands, it will be processed before the others. Here is an example:
// ... as before
calico::producers::image_producer_callback::image_producer_callback(so_5::agent_context_t ctx, so_5::mbox_t channel, so_5::mbox_t commands)
: agent_t(std::move(ctx) + so_5::priority_t::p1), m_channel(std::move(channel)), m_commands(std::move(commands))
{
}
// ... as before
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(disp::prio_one_thread::strictly_ordered::make_dispatcher(env.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer_callback>(main_channel, commands_channel);
c.make_agent<stream_detector>(mbox);
c.make_agent<image_tracer>(mbox);
c.make_agent<face_detector>(mbox);
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
Another classic example involves a pair of agents: one tasked with processing operations and the other responsible for handling a “new configuration” command. In this scenario, when the “new configuration” command is received, it’s essential to handle it promptly. A priority schema is well-suited to address this requirement.
While this mechanism is effective in many cases, there are scenarios where one or more agents experience starvation, as high priority agents might jeopardize the working thread. For example, suppose we also mark image_producer_recursive with higher priority than other agents. We recall that image_producer_recursive always sends a message to itself after sending the current frame to the output channel:
st_started.event([this](so_5::mhood_t<grab_image>) {
cv::Mat image;
if (m_capture.read(image))
{
so_5::send<cv::Mat>(m_channel, std::move(image));
}
else
{
so_5::send<device_error>(m_channel, "read error", device_error_type::read_error);
}
so_5::send<grab_image>(*this);
})
This implies that assigning the agent a higher priority and binding it to a strictly_ordered dispatcher alongside other agents will prevent other demands from being processed! The producer would monopolize the event queue.
In this scenario, another potential solution is provided by prio_one_thread::quote_round_robin, which operates on a round-robin principle: it permits specifying the maximum count of events to be processed consecutively for the specified priority. Once this count of events has been processed, the dispatcher switches to handling events of lower priority, even if there are still higher-priority events remaining. This way, we might still give image_producer_recursive a higher priority than others but we can limit its demands to – let’s say – 1.
Another example where this dispatcher is useful is one where we manage clients with different tiers on service quality, such as the API subscription to a certain service. For example, tier-1 (or “premium”) clients require first-class quality of service, while others may have lower demands for service quality. By assigning a high priority to agents handling premium client requests and specifying a large quote for that priority, more requests from premium clients will be handled promptly. Meanwhile, agents with lower priority and a smaller quote will address requests from other clients, ensuring a balanced processing of requests across all client types.
Finally, an additional strategy is given by prio_dedicated_threads::one_per_prio which creates and manages a dedicated thread for each priority. For example, events assigned to agents with priority p7 will be processed on a separate thread from events assigned to agents with, for instance, priority p6. Events inside the same priority are handled in chronological order.
This dispatcher provides the capability to allocate threads based on priority. For instance, in a particular scenario, we might assign a certain priority to troubleshooting or diagnostics agents like image_tracer or stream_heartbeat, while assigning a different priority to “core” agents like face_detector and image_resizer. It’s important to note that priorities are implementation details of agents, meaning the only way to inject priority to an agent from outside is by taking a parameter that represents the priority in the agent’s constructor. For example:
some_agent(so_5::agent_context_t ctx, so_5::priority_t priority, ...)
: agent_t(ctx + priority), ...
{
}
Thus, unlike binding agents to dispatchers, priorities are not inherently separated from agent implementation details. However, we can still inject priority from outside if we create the agent “by hand”, (when the agent accepts agent_context_t in the constructor):
auto agent = make_unique<my_agent>(agent_context_t{env} + priority_t::p2, ...);
This way, when utilizing third-party or unmodifiable agents, incorporating priorities into existing agents is feasible.
In conclusion, priorities provide an additional dimension to consider when aiming to minimize the number of threads or when binding agents to threads might be based on priority. Some examples of good questions to ask here are: “is there any agent in the group requiring more special than others in terms of responsiveness?” or “could we assign agents to threads based on some fixed partition schema (such as assigning a sort of label to each agent)?”.
However, there are situations where binding an agent to a shared thread does not inherently pose an issue, but rather, distributing its workload across multiple threads presents an opportunity. For example, serving multiple clients of our gRPC service in parallel.
In the next section, we’ll share some thoughts about this essential dimension.
Using multiple threads
There are scenarios where breaking down a specific task into multiple parallel executions offers tangible benefits. A classic example is the “Scatter-Gather” pattern, where an operation is divided into subtasks that are concurrently executed by multiple workers, and their results are combined for further use. Similarly, in other cases, several coarse-grained operations are simply executed in parallel by independent workers. For instance, in our gRPC service, we spawn an agent to manage each client’s conversation.
Discussing SObjectizer, we’ve discovered various tools for distributing work across multiple workers. These options range from independent agents receiving messages from a message chain to a single agent with thread-safe handlers, and even more complex solutions involving a “task coordinator”.
We typically resort to dispatchers like thread_pool or adv_thread_pooladv_thread_pool when leverage thread_safe handlers is necessary.
Alternatively, as seen with image_saver, we spawn a fixed number of agents each bound to a dedicated thread using active_obj. Usually, a thread pool provides greater flexibility and options for fine-tuning, but the same considerations discussed earlier regarding the advantages of a dedicated thread per agent remain relevant.
The considerations we share in this section are for choosing the dimension of the pools, depending on the different scenarios we are facing. Determining the appropriate size for thread pools is more of an art than a science, but it’s essential to avoid extremes such as being overly large or too small. A thread pool that is too large may lead to threads competing for limited CPU and memory resources, resulting in increased memory usage and potential resource exhaustion. Conversely, a pool that is too small can impact throughput, as processors remain underutilized despite available tasks to be executed. Striking the right balance is key to optimizing performance and resource utilization.
Clearly, this is a broad and complex topic, and this post merely scratches the surface.
First of all, we should distinguish between CPU-bound and I/O bound tasks. Computationally intensive tasks, such as complex mathematical calculations, are considered CPU-bound, while operations that require waiting for external processes, like network requests, fall under the category of I/O-bound tasks. In such scenarios, efficient CPU utilization entails the ability to switch to other threads during periods of waiting, optimizing the use of available computational resources.
Usually, thread pools designated for CPU-bound tasks are sized to match the number of available CPU cores number_of_cores or a number close to that (+1, -1 or -2).
On the other hand, for I/O-bound operations, having more threads than the number of CPU cores is advantageous. This surplus allows for continuous activity on the CPU cores, even when some threads are blocked waiting for I/O operations. With additional threads available, new operations can be initiated, maximizing CPU resource utilization. This overlap in I/O tasks prevents idle time and optimizes the execution of I/O-bound tasks.
In this regard, a popular formula from Brian Goetz’s book is:
number_of_threads = number_of_cpus * target_cpu_util * (1 + wait_time / service_time)
Where:
number_of_cpusis the number of available CPUs (e.g. cores);target_cpu_utilrepresents the wanted CPU utilization, between 0 and 1 (inclusive);wait_timeis the time spent waiting for IO bound tasks to complete (e.g. awaiting gRPC response);service_timeis the actual time spent doing the operation.
The ratio of waiting time to service time, commonly referred to as the blocking coefficient, represents the proportion of time spent awaiting the completion of I/O operations compared to the time spent on doing work. If a task is CPU-bound, that coefficient is close to 0 and having more threads than available cores is not advantageous. The target_cpu_util parameter serves as a means to maintain the formula’s generality, particularly in scenarios involving multiple thread pools. For example, if there are two pools we might set the target_cpu_util value to 0.5 to balance the utilization on both.
The blocking coefficient must be estimated, which doesn’t need to be precise and can be obtained through profiling or instrumentation. However, there are some other cases where finding a suitable pool size is simpler and doesn’t require applying the formula above.
A first scenario is like those encountered in calico, where interfacing with external hardware devices is necessary. In such cases, a common approach involves dedicating a separate thread for each device. For instance, if calico managed multiple cameras using “blocking” APIs, we might dedicate a thread for each camera to ensure efficient handling of device interactions.
Another pertinent consideration, not confined to the aforementioned scenario, arises when tasks depend on pooled resources such as driver connections, such as databases. In this case, the size of the thread pool is constrained by the size of the connection pool. For example, does it make sense to have 1000 active threads when the database connection pool can only accommodate 100 connections? Probably not.
Finally, there are scenarios where we are required to estimate the number of workers given the target throughput. In other words, we should understand how the number of parallel workers influences latency and throughput. Little’s law can provide insight into this topic. It states that the number of requests in a system is equal to the arrival rate multiplied by the average time taken to service a request. By applying this formula, we can determine the optimal number of parallel workers required to manage a predetermined throughput at a specific latency level. The formula is here below:
L = λ * W
Where:
- L is the number of requests to process simultaneously;
- λ is the arrival rate (number of incoming tasks per time unit – e.g. 20fps);
- W is the latency, or the average time taken to process a single request (e.g. 0.5s).
For example, if we consider a scenario where each operation requires 500 millisecond to complete (W), with a desired throughput of 20 fps (λ), we would need a thread pool with at least L = λ*W = 10 threads to handle this workload effectively. This formula can also serve to calculate the maximum throughput given the number of workers and average latency. Consider that SObjectizer’s telemetry capabilities discussed in the previous article might be helpful to estimate W.
In conclusion, when we have CPU-bound or I/O-bound operations that benefit from parallelization, we might consider thread pools or dedicated threads. Good questions to answer here are: “is the agent performing CPU-bound or I/O-bound tasks?” or “if throughput is an issue, is it feasible and beneficial to distribute work?”.
The next two sections explore a few additional scenarios that arose from a private conversation with Yauheni.
Sharing thread enables sharing data
Binding agents to the same thread brings another opportunity that was mentioned by Yauheni:
“It’s not a good thing in the Actor Model, but it’s the real life and sometimes we have to hold references to some shared mutable data in several agents. To simplify management of this shared data we can bind all those agents to the same worker thread”.
My initial assumption was that when adopting the actor model, we generally aim to minimize shared state as much as possible. However, as discussed in earlier posts, there are scenarios where shared state is unavoidable or hard to remove. In such cases, SObjectizer offers features to facilitate the effective management of shared state. I’m not suggesting that you take this matter lightly, but rather emphasizing that if avoidance is truly impractical, I share that SObjectizer provides tools to simplify the process and to make shared state more manageable.
In this regard, we can bind agents that share a common state to the same thread by utilizing dispatchers like one_thread, active_group, or a thread pool with cooperation FIFO. SObjectizer ensures that these agents will never be scheduled simultaneously, thereby guaranteeing the integrity of shared state management without necessitating locks nor atomics. The reason is clear: since all the agents involved run on the very same thread, there is no chance to access shared resources from different threads.
Consider our “routing slip” or “pipes and filters” pipelines. If the agents involved need to share data, leveraging the shared thread could be a suitable approach.
Special context requirements
Once again, Yauheni shared a valuable piece of his extensive experience:
“Some actions might need to be taken from a specific thread. For example, drawing to screen can be done from the main thread only. So we have to bind several agents to a dispatcher that schedules them on the right thread”.
In this case, it’s possible that we need to craft and use a custom dispatcher for the purpose. This might be not an easy task in general but we know where to start as we learnt in this previous post. For example, in calico we have discussed and crafted a do_gui_message_loop() function to guarantee the OpenCV drawing happens on the calling thread – and we call this function from the main thread. An alternative solution consists in developing a customized dispatcher. Just to share another example, SObjectizer’s companion project so5extra, provides some battle-tested dispatchers tailored for boost ASIO.
Yauheni also shared an additional scenario:
“Some 3rd party libraries must be used from one thread only. For example, a library may require calls like lib_init/lib_deinit to be performed from the same thread. Sometimes other calls from the library should be taken from the same thread too (because the library uses thread local variables under the hood). This requires us to bind agents to one_thread or active_group dispatcher”.
Since there isn’t a strict requirement for a specific thread to be utilized, but rather for certain operations to be executed on the same thread, there’s no necessity for us to develop our own dispatcher. As Yauheni suggested, we can leverage existing options such as one_thread or active_group dispatchers to fulfill this requirement.
A complete example
Before concluding, we apply some of the ideas discussed above to calico. We propose to set up the program as follows:
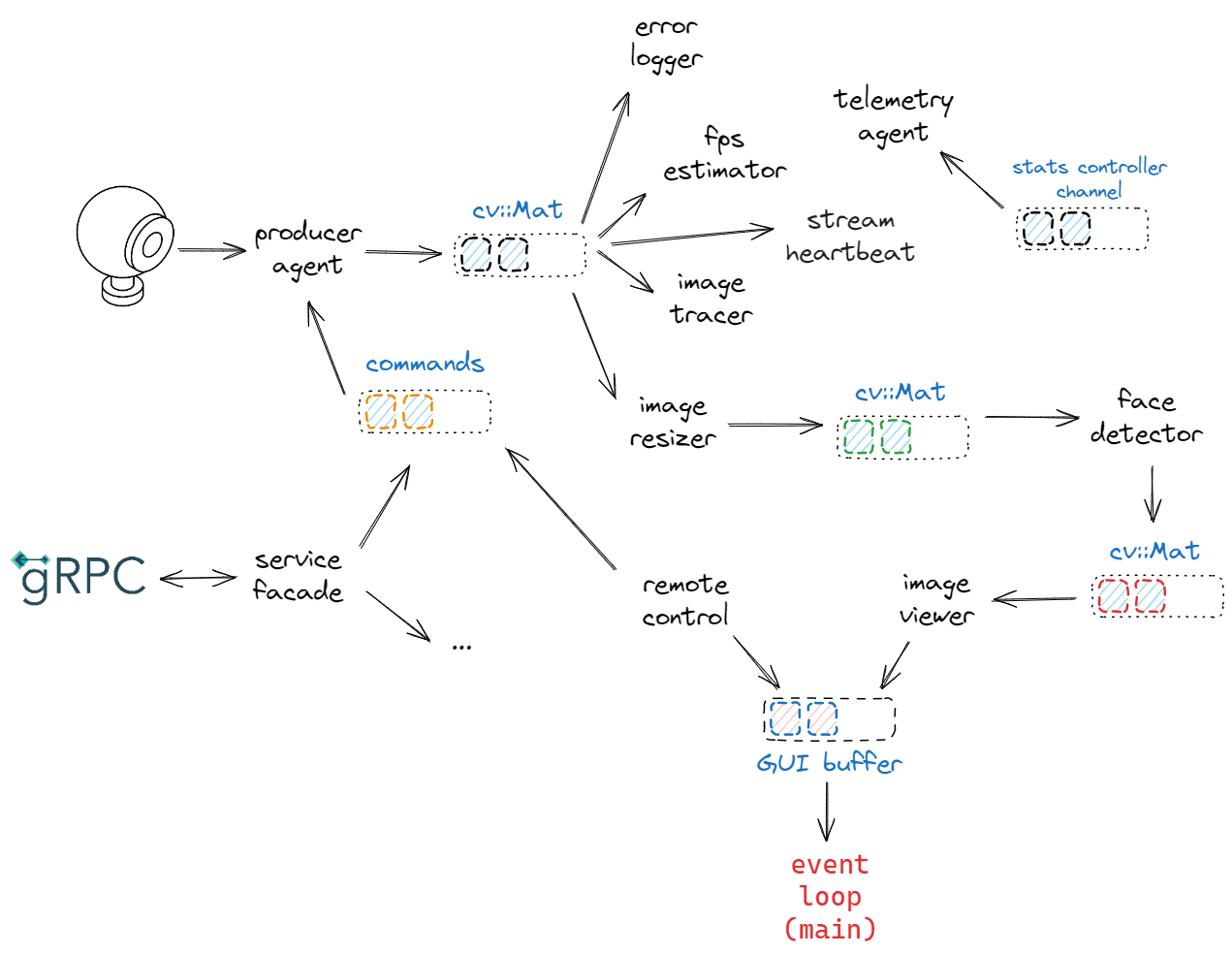
In essence:
- a producer agent – suppose it’s the “blocking” one – sends images to the named “main” channel and gets commands from the named “commands” channel;
- a
remote_controlgets command from the “UI”; - a
service_facadeenables external client to interact with the program; - “main” channel is subscribed by a bunch of agents that boil down as follows:
- a “core” path that pass through an
image_resizerthat feeds aface_detectorwhose output is visualized to the screen usingimage_viewer; - a “support” path where
image_tracer,fps_estimator,stream_heartbeatanderror_loggercontribute to monitor the system; - a
telemetry_agentis also installed to display some telemetry data on demand;
- a “core” path that pass through an
- the usual event loop from main handles the GUI messages.
We start with binding all the agents to the same the thread:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_channel("main");
const auto commands_channel = sobjectizer.environment().create_channel("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
const auto waitkey_out = sobjectizer.environment().create_mbox(constants::waitkey_channel_name);
sobjectizer.environment().introduce_coop([&](coop_t& c) {
c.make_agent<image_producer>(main_channel, commands_channel);
c.make_agent<remote_control>(commands_channel, message_queue);
c.make_agent<service_facade>();
c.make_agent<image_tracer>(main_channel);
c.make_agent<fps_estimator>(std::vector{ main_channel });
c.make_agent<telemetry_agent>();
c.make_agent<stream_heartbeat>(main_channel);
c.make_agent<error_logger>(main_channel);
const auto faces = c.make_agent<face_detector>(c.make_agent<image_resizer>(main_channel, 0.5)->output())->output();
c.make_agent<image_viewer>(faces, message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
At this point, we proceed with the “rebinding” phase.
The first question we typically ask is “which agent shouldn’t be blocked by others and vice versa?”. We identify two agents:
image_producer, since it blocks its thread all the time, we have no other choice;service_facade, since starting and stopping the server might block, we decide to give it a dedicated thread.
The picture changes slightly:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_channel("main");
const auto commands_channel = sobjectizer.environment().create_channel("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
const auto waitkey_out = sobjectizer.environment().create_channel(constants::waitkey_channel_name);
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer>(main_channel, commands_channel);
c.make_agent<service_facade>();
});
sobjectizer.environment().introduce_coop([&](coop_t& c) {
c.make_agent<remote_control>(commands_channel, waitkey_out, message_queue);
c.make_agent<image_tracer>(main_channel);
c.make_agent<fps_estimator>(std::vector{ main_channel });
c.make_agent<telemetry_agent>();
c.make_agent<stream_heartbeat>(main_channel);
c.make_agent<error_logger>(main_channel);
const auto faces = c.make_agent<face_detector>(c.make_agent<image_resizer>(main_channel, 0.5)->output())->output();
c.make_agent<image_viewer>(faces, message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
Now, from the remaining agents, we speculate about which ones are “cheap” or might be tolerant to delays:
remote_controlreroutes messages;image_tracerprints to the console and, in general, is a “monitoring” agent;fps_estimatoris cheap, reacts to periodic events, and is a “monitoring” agent;telemetry_agentreacts to slow rate events and is a “monitoring” agent;stream_heartbeatreacts to slow rate events and is a “monitoring” agent;error_loggerprints to the console and should react to sporadic events;image_resizeris CPU-bound;face_detectoris CPU-bound;image_viewerreroutes messages;
Here are a few observations:
- with the term “monitoring” agent we mean that, in this context, the agent doesn’t perform any “core” operations and may tolerate some delays;
- we assume these agents don’t execute “blocking” operations, although writing to the console could potentially block;
- the
error_loggercurrently lacks the logic to send an alert in case of catastrophic failures or the reception of several errors in quick succession. While it may be acceptable for it to experience delays in our scenario, it might need to be more responsive in general.
Considering these factors, it appears that we can group all of these agents together into a kind of “monitoring” cooperation. However, we would exclude remote_control from this group since it represents a crucial part of the core business. Indeed, separating monitoring agents from others offers convenience, especially if we need to deallocate all of them together:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_channel("main");
const auto commands_channel = sobjectizer.environment().create_channel("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
const auto waitkey_out = sobjectizer.environment().create_channel(constants::waitkey_channel_name);
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(env.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer>(main_channel, commands_channel);
c.make_agent<service_facade>();
});
sobjectizer.environment().introduce_coop(disp::active_group::make_dispatcher(sobjectizer.environment()).binder("monitoring"), [&](coop_t& c) {
c.make_agent<image_tracer>(main_channel);
c.make_agent<fps_estimator>(std::vector{ main_channel });
c.make_agent<telemetry_agent>();
c.make_agent<stream_heartbeat>(main_channel);
c.make_agent<error_logger>(main_channel);
});
sobjectizer.environment().introduce_coop([&](coop_t& c) {
c.make_agent<remote_control>(commands_channel, waitkey_out, message_queue);
const auto faces = c.make_agent<face_detector>(
c.make_agent<image_resizer>(main_channel, 0.5)->output()
)->output();
c.make_agent<image_viewer>(faces, message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
Here is a picture of the different thread allocations:
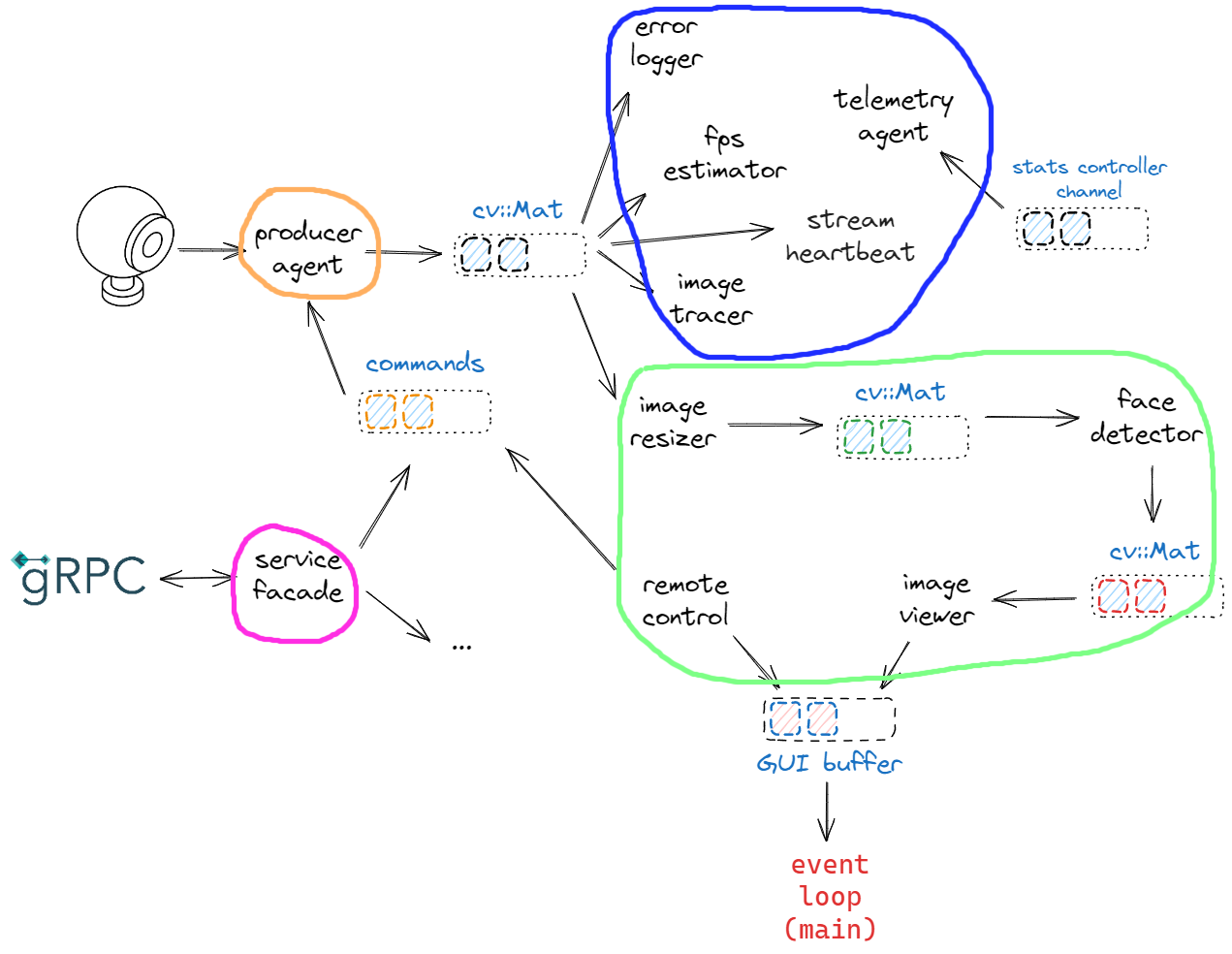
The remaining agents might be bound to another active_group dispatcher or left with the one_thread dispatcher. Note that the core part of the system consists of the (sequential) pipeline:
image_resizerface_detectorimage_viewer
An alternative option would be to allocate a dedicated thread for this pipeline, particularly if there are multiple pipelines in the system. As the system expands and additional pipelines are introduced, it may be advantageous to assign all of them to a thread pool, which can manage threads more efficiently. Additionally, when managing multiple pipelines with varying service requirements, it’s convenient to consider agent priorities.
Finally, let’s review service_facade, which internally utilizes a thread pool. Specifically, each subscribe_client_agent is associated with a common thread pool of 4 threads. This aspect is worth some discussion. Firstly, given that the gRPC synchronous API is pooled, we may want to limit the number of threads to match the size of the library’s pool. By default, gRPC creates a thread for each CPU core and dynamically adjusts the thread count based on workload. We can configure this behavior to some extent and align our thread pool accordingly.
Another approach to sizing the pool involves applying Little’s law to approximate the number of workers needed to achieve a target throughput. To estimate latency, we can enable telemetry on the thread pool and observe thread activity under different workloads. For example, when subscribing to the gRPC service from 8 clients using a pool of 4 threads, the average latency per thread is approximately 5 milliseconds. This implies that to maintain a throughput of 500 requests per second, we should size the pool with 25 workers. However, this value should be adjusted to accommodate gRPC’s thread pool size, and then some other tests should be performed.
It was a long journey but we hope to have shared some useful ideas and good questions to ask when it’s time to select dispatchers.
The series is nearing its conclusion, and in the next post, we’ll delve into some design considerations and share additional ideas to assist you in designing SObjectizer-based systems more effectively.
Takeaway
In this episode we have learned:
- dispatcher binding is a crucial decision when designing SObjectizer-based systems and actor model applications in general;
- by default, SObjectizer binds all agents to the same thread, but it’s essential to consider alternatives based on specific requirements;
- a method for determining dispatcher selection involves asking questions about agent traits and system requirements;
- the first question concerns potential blocking: could an agent be blocked by others, or vice versa? If not, a dedicated thread may be necessary;
- the second question relates to agent priorities: can a priority schema help avoid unnecessary thread allocation? Assigning priorities to agents and using corresponding dispatchers may be beneficial;
- the third question addresses workload distribution: is the agent CPU-bound or I/O bound? Depending on the answer, distributing tasks across multiple threads or using thread pools can enhance system throughput;
- lastly, it’s worth considering additional dimensions such as shared state management and constraining execution to specific threads. Shared state can be managed using shared threads, while constraints on execution threads can be addressed with custom dispatchers or those allocating only one thread, like
one_threadandactive_group; - by considering these “dimensions”, developers can make informed decisions about dispatcher binding and optimize the performance of their SObjectizer-based systems.
As usual, calico is updated and tagged.
What’s next?
After spending some time we Ronnie, we realize there are other important considerations to share about designing systems with SObejctizer and some general ideas that holds for any applications developed using the actor model and messaging.
In the next post, we’ll delve into these topics further.
Thanks to Yauheni Akhotnikau for having reviewed this post.
