Never did I imagine crafting 30 episodes. Initially, I planned for a modest 15 or perhaps 20 episodes, but my willingness for sharing led me down an unexpected path of creativity. Despite the likelihood of limited readership due to its length and niche topic, I am ok with that. Yet, above all, I embarked on this endeavor for my own growth and self-expression. It began last August, during a well-deserved break before my holiday adventures commenced, and remained with me for more than six months.
The series was for me like a boat to traverse the river, but now that I’ve reached the other shore, it must be left behind as I cannot bear its weight on my back to continue my journey on foot.
Before diving into this final installment, I want to express my gratitude once more to Yauheni Akhotnikau. Beyond being a reviewer, I believe I’ve found a friend in him. Throughout each episode, Yauheni not only provided feedback but also engaged in meaningful exchanges about life. I am thankful for the chance to connect with him on a deeper level.
This final post is structured as follows: first, we offer a brief recap of the series; next, we present an overview of missing features that were not covered throughout the series; finally, we give some suggestions for initiating work with SObjectizer and the paradigm in general.
TL;DR: Rewind
The series focused on developing calico, a program tailored for acquiring and processing images from a camera – specifically, the default webcam on our machine. Utilizing SObjectizer, we encapsulated logic within self-contained actors (agents) that communicated via messages, following the publish-subscribe pattern. SObjectizer managed actor and channel lifecycles, data distribution, and agent logic execution on threads, employing dispatchers to meet our requirements.
Collaborating with colleagues, we incrementally added new features, exchanged ideas, and expanded our knowledge. Each post explored a specific aspect of calico and introduced corresponding features of SObjectizer that facilitated its development, occasionally allowing for broader reflections. Ultimately, calico emerged as a versatile environment where various and original functionalities could be achieved by combining actors through channels.
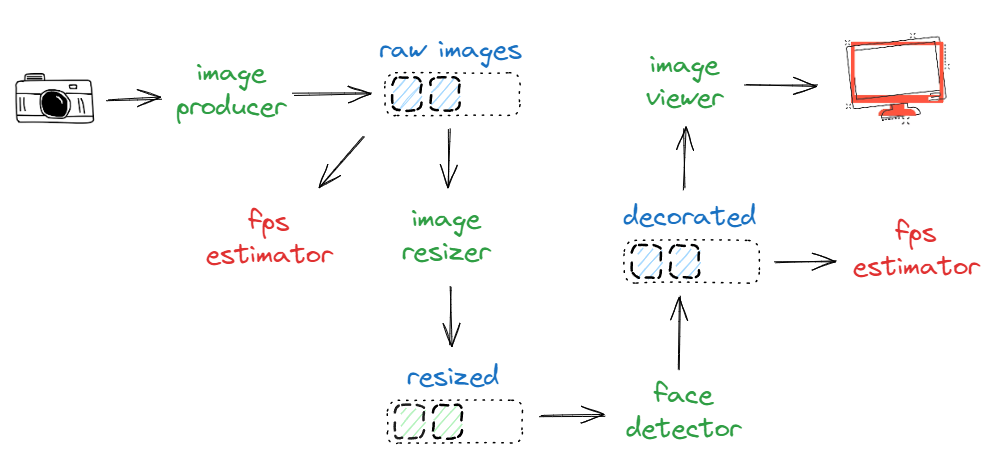
First, we discussed the implementation of 4 image producers:
image_producer: implementing a tight acquisition loop employing the “blocking” camera API;
image_producer_recursive: implementing a message passing-styled loop with the “blocking” camera API;
image_producer_callback: employing the “non-blocking” camera API;
virtual_image_producer: implementing a message passing-styled loop with a simulated “blocking” API, reading images from the disk;
Then, we delved into the development of an extensive set of processing agents for various functionalities, occasionally touching upon broader themes as they arose. Here’s a breakdown:
Core:
face_detector: detects faces in frames and overlays them (or nothing if none detected);
image_cache: caches images until a certain dimension is reached;
image_resizer: resizes images;
image_saver: Saves images to disk;
service_facade: enables external processes to receive images and to send commands via gRPC;
static and dynamic processing pipelines: demonstrates “pipes and filters” and “routing slip” patterns;
stream_detector: provides signal-based logic to detect streaming start and stop.
UI:
image_viewer and live_image_viewer: display images (and also their counterparts that run on the main thread only);
remote_control: sends commands using keyboard (and also its counterpart that runs on the main thread only).
Monitoring:
error_logger: logs any image acquisition error to console;
fps_estimator: estimates and logs the frame rate of any channel;
image_tracer: logs images received from any channel;
stream_heartbeat: logs the uptime of a stream from any channel;
telemetry_agent: demonstrates the usage of runtime telemetry.
Most of these agents support input channels, and some also support output channels. For example, image_viewer receives images from an input channel but does not output to any channel. Conversely, image_resizer takes input images and sends resized frames to an output channel.
When we say “channels” we mean “message boxes”, which are the main abstraction in SObjectizer for transmitting messages and signals.
This design offers powerful features. Firstly, encapsulation is achieved, as agents communicate solely through messages without direct knowledge of each other. This allows for versatility, such as feeding agents with images from any source, including test cases, for example. Secondly, the design promotes extensibility by enabling the addition of new agents without altering existing ones. Introducing a new feature may only require the development of a new agent. Additionally, the paradigm’s flexibility extends to thread binding, as agents aren’t inherently tied to specific threads. Users have the flexibility to assign agents to worker threads as needed, even dynamically. Finally, this model simplifies concurrent code, as agents ideally don’t share state. Synchronization is handled by the framework solely on message queues, eliminating the need for explicit synchronization mechanisms.
In calico, the instantiation and combination of agents are hard-coded. However, supporting dynamically-loaded configurations to generate processing pipelines at runtime would be relatively simple to implement and it’s exactly what I have developed in my real scenario.
Furthermore, during the series we explored broader topics such as testing, measuring performance, shutdown prevention, binding agents to threads (dispatchers), and various high-level design considerations and patterns. Concluding our series, we discussed aspects of SObjectizer that we found less favorable or areas where we envisioned potential improvements.
At this point, let’s briefly touch upon a few features that weren’t explored throughout the series.
Missing features carousel
We now briefly explore some features that weren’t covered in the series because they weren’t necessary for my purposes. However, they may offer solutions to specific problems and should be taken into account for future projects. I’ve categorized these features into two groups: ordinary and advanced.
In the ordinary category:
Message Delivery Tracing aims to debug an application built on top of SObjectizer. In essence, it logs the primary stages of the message delivery process, allowing visibility into whether there is a suitable subscriber with the corresponding event handler.
Deadletter Handlers is a shorthand for handling the same message in the same way from different states of the same agent. For example, instead of this:
Unique Subscribers Message Box – recently brought from so5extra to SObjectizer – is a special MPSC message box, permitting subscription from multiple agents as long as they subscribe to different messages. This enables each handler to handle mutable messages. This capability is especially valuable in processing pipelines. For instance, consider a data-processing scenario with multiple processing stages, each represented as an agent, and a coordinating agent managing the processing through mutable messages: the manager sends a message to the first stage agent, receives the result, then forwards a message to the second stage agent, and continues in this manner.
Due to the necessity of mutable messages, only MPSC mailboxes are viable. However, this requires the manager to know MPSC mailboxes for each processing stage, which can be inconvenient. While it would be simpler to have a single mailbox for all outgoing mutable messages, the standard MPMC mailbox permits subscription from different agents but does not support mutable message exchange. Here is where unique subscribers message boxes come into play.
Custom Direct Message Box enables programmers to construct an agent’s direct message box, instead of using the default one provided by SObjectizer.
In the advanced category, we find low-level features that cover uncommon use cases:
Custom Worker Threads enables to replace underlying thread implementation used by dispatchers.
Event Queue Hooks enables the creation of specialized wrappers around event queues, which can serve various purposes such as tracing and collecting runtime statistics.
Environment Infrastructures allows for the specification of the threading strategy within SObjectizer’s environment. By default, there are at least three background threads: one for the default dispatcher, another for timers (the timer thread), and an additional thread for completing deregistration operations. Furthermore, SObjectizer provides the option to choose a single-threaded environment, which can be either thread-safe or not, tailored for specific use cases.
Subscription Storage is a fundamental data structure within SObjectizer, responsible for storing and managing subscription information for each agent. Depending on the use case, agents may create varying numbers of subscriptions, ranging from a few to potentially thousands. Therefore, the choice of data structure is crucial. SObjectizer offers flexibility in selecting different storage options, including vector-based, map-based, hash-based, etc. By default, the strategy is adaptive: for agents with few subscriptions, a small and fast vector-based storage is utilized. However, as the number of subscriptions grows, the agent automatically switches to a more suitable, albeit more resource-intensive, map-based storage solution.
Locks Factory is an advanced tool for selecting different event queue synchronization schemas. The functionality extends beyond data protection to include notification of consumers about the arrival of new events. While the default synchronization scheme is efficient under heavy loads, it may not be optimal for certain load profiles. SObjectizer addresses this issue by enabling the specification of another simpler locking schema that is based on mutexes and condition variables that might be more lightweight for some use cases.
Enveloped Messages allows the transmission of messages or signals enclosed within a special object known as an “envelope”. These envelopes can carry additional information and execute specific actions upon delivery of the message/signal to a receiver. This is considered a low-level feature primarily intended for use by SObjectizer’s developers or by those seeking to extend its functionality.
Where to go from here
Are you interested in utilizing SObjectizer? Are you seeking inspiration for practicing with this paradigm? In this concise section, we’ll provide you with some ideas to explore.
To begin with, consider utilizing calico as your personal gym, as its development journey may still have more to offer. There are several areas left for further enhancement. These include introducing missing tests, implementing dynamic pipeline generation as previously mentioned, adding new agents for currently unsupported operations, supporting multiple cameras or devices, and more. The possibilities for expansion are virtually limitless.
Additionally, consider starting your own project. Identify a use case and experiment with leveraging SObjectizer and its supported paradigms to develop it. Concurrency might be simpler if you think of it as individual actors exchanging messages. Seeking ideas?
interactive chat
simple games
message broker
video streaming application
Another valuable exercise involves reviewing others’ code. You can explore the “by example series” in the official wiki, which demonstrates more advanced use cases of SObjectizer. Additionally, there are various open-source projects that leverage SObjectizer, offering inspiration and insight into its practical applications, such as:
LabNet, a server to control hardware connected to RaspberryPi over Ethernet.
Furthermore, consider rethinking an existing concurrent application through the lens of SObjectizer and its capabilities. Does it fit well? What functionalities are lacking? Remember that the SObjectizer community is readily available to assist you.
Finally, I summarize a thoughtful remark by Yauheni regarding the adoption of SObjectizer. He emphasizes that the main issue with SObjectizer is its lack of widespread experience and visibility on the internet, making it prone to misuse and resulting in poor outcomes. He advises gaining experience with SObjectizer before using it extensively in serious development. For new projects, he suggests that the lack of experience is less critical as initial development phases allow for experimentation and quick fixes. Yauheni highlights the risk of integrating SObjectizer into large, established projects without sufficient expertise and suggest two safer approaches: first, using SObjectizer for auxiliary tasks like writing emulators to gain experience, and second, encapsulating SObjectizer functionalities within isolated subsystems with familiar interfaces to ensure flexibility in case of integration issues. This strategy allows for safe adoption and potential changes if integration problems arise.
Last but not least, whether you have questions or seek design advice, don’t hesitate to open an issue for support and discussion. Sometimes, as happened to me several times, such questions turn into new features.
See you next time!
Have you read the entire series or maybe just some episodes?! I’d love to hear your thoughts!
Would you like to see more content like this? What aspects did you enjoy the most and which ones the least about the series? Please reach out via email or leave a comment here with your feedback!
During our way back home, just before reaching the corporate parking lot, we bumped into Dan, an experienced developer who recently explored SObjectizer to help the team enhance some aspects of calico. Dan used the library for a while and now he is eager to share his feedback on what he finds most challenging or frustrating.
In this article, we’ll delve into Dan’s complaints to offer a perspective on certain features and aspects that can be awkward. As the author of this series, I believe it’s essential to candidly discuss areas where I feel less comfortable with the library and, sometimes, suggest potential improvements from a user’s standpoint. The opinions in this article are my own and might be different from what other people think about SObjectizer.
Dropping work at shutdown
The most notable missing feature for me is the automatic interruption of agent’s work at shutdown. This issue strikes a nerve with me, given that I often work on backend services requiring rapid shutdown, particularly in the context of modern deployment options like Docker. As discussed in a previous article, pending events in an agent’s queue will be processed at some point, even though the shutdown procedure is triggered. Therefore, if we need to drop pending messages, we must design agents accordingly to do so. However, all the solutions we discussed are essentially workarounds that require mixing agent logic with message management, often leading to a violation of the Single Responsibility Principle (SRP). While we may introduce more generic solutions to address this issue, they would inevitably involve some degree of SRP violation and may not be a standard solution in every case.
While I don’t have a specific proposal for implementing this feature into SObjectizer, as it would necessitate significant changes to its internals, I do have a suggestion for enabling it. We could introduce an optional “drop events at shutdown” toggle on the context object, similar to how message limits and agent priorities are configured:
class my_agent final : public so_5::agent_t
{
public:
my_agent(so_5::agent_context_t ctx)
: agent_t(ctx + drop_events_at_shutdown), ...
Akin to other toggles, the drop_events_at_shutdown is a “hint” for dispatchers to understand that the particular agent needs to drop any pending demands at shutdown. This means, the dispatcher should just discard any pending messages awaiting processing during the shutdown process. Also, this approach would allow for an incremental implementation. It could start with a spike for a specific dispatcher and then be extended to others if deemed necessary.
If I had a magic wand…I would introduce a feature that allows configuring agents to drop pending work at shutdown. This feature would be available on any dispatcher, similar to message limits, providing more control over shutdown behavior.
SObjectizer Lite
SObjectizer makes extensive use of features like RTTI, exceptions, dynamic dispatching, and heap allocations, which are essential for its expressiveness and power. However, these features also limit its usability in scenarios where they are not permitted, such as deterministic systems like embedded and real-time environments.
This wish is highly utopic, as it would necessitate a complete redesign of the entire framework. Moreover, achieving the same level of functionality without the aforementioned C++ features is practically unfeasible. However, maybe it would be possible at some point to create a subset of SObjectizer – a sort of “SObjectizer Lite” – that is implemented only in terms of some allowed C++ features.
If I had a magic wand…I would provide a “SObjectizer Lite” version tailored for real-time systems.
Telemetry is not strongly typed
When I bumped into SObjectizer’s runtime monitoring feature for the first time, I appreciated the consistency of telemetry data being sent as messages to a predefined message box. However, I found it somewhat cumbersome that filtering different quantities required working with strings. I understand that using a single type, like quantity<T>, is an effective and future-proof way to represent telemetry data. For instance, if we need to store all telemetry information blindly to a non-relational database, we can simply subscribe to quantity<size_t> and receive everything.
However, I believe that quantity should also contain a stronger type identifier for the kind of data transmitted, such as “demand count” or “active_obj event count”. While I don’t have strong opinions on this matter (it might be a scoped enumeration or something else), I would prefer to avoid using strings for filtering such information, especially standard information not provided by the user.
If I had a magic wand…I would strengthen telemetry data type by adding more information in order to simplify and make filtering more efficient.
Default handlers
A nice thing to have for me is the possibility to subscribe for “any” message type. My idea for the syntax would be either:
mhood_t<void>
That would not require introducing any special type, or:
mhood_t<unhandled>
where unhandled is provided by SObjectizer. Another alternative could involve using std::any, enabling functions like any_cast() and others. However, I’m not particularly fond of these techniques as they can often be seen as design shortcuts that may lead to complications later on.
One possible use case for this feature is discussed in the previous article, primarily to address agents like image_tracer or fps_estimator, which only need to observe traffic over a channel. Conversely, another useful scenario where this type might come in handy is the opposite case: ensuring that only certain types of messages are sent to a channel:
Here above, if types other than string and my_message are sent to m_channel, an exception will be thrown. This approach could prove useful for maintaining control over the design and, upon introducing a new message type into the system, breaking the program, possibly first by running unit tests.
If I had a magic wand…I would introduce a way to subscribe for a default message type.
Different channel abstractions
mbox_t serves as a powerful and unified abstraction, representing a versatile carrier for both messages and signals. However, it’s important to note that behind the scenes, message boxes come in three distinct flavors:
Multi-Producer Multi-Consumer: these message boxes can be subscribed to by any “sink” (e.g. agent), and any entity can send them a message;
Multi-Producer Single-Consumer: these message boxes can only be subscribed to by their “owner”, but any entity can still send them a message;
Converted from message chains: these message boxes cannot be subscribed to by any entity, but any entity can send them a message.
While I understand the convenience of having only a single type, mbox_t, to pass around, I must raise a concern about the resulting design. It could potentially be confusing, as it requires knowing exactly which “kind” of mbox_t we are dealing with, especially when inheriting code. Typically, this necessitates examining the source code or referring to documentation (if available). The primary concern is that mbox_t effectively acts as a weaker type, causing so_subscribe() to behave differently based on internal information that cannot be retrieved at compile-time.
Thus, another design – clearly more intrusive – would be to introduce a hierarchy, such as:
mbox_sink: corresponding to the third flavor mentioned above, only allows data to be sent to it; attempting to subscribe to it would result in a compilation error;
mbox_single_target, corresponding to the second flavor mentioned above, inherits from mbox_sink and adds the capability to subscribe to it from a single agent. Although it’s not possible to enforce checking the “owner” at compile-time, static analysis can help identify issues;
mbox_multi_target, corresponding to the first flavor mentioned above, inherits from mbox_single_target and adds the capability to subscribe to it from any entity.
In practice:
mbox_sink is created when a message chain is converted to a message box using as_mbox().
mbox_single_target is the result of calling so_direct_mbox() on any agent.
mbox_multi_target is the result of creating a Multi-Producer Multi-Consumer (MPMC) channel, such as calling environment.create_mbox().
The initial proposal for this could involve using type aliases. All such types could simply be aliases of mbox_t, with the mentioned functions returning them as appropriate. While errors wouldn’t be prevented at compile-time, users could opt to use these aliases to make their intentions a bit more expressive.
If I had a magic wand…I would introduce stronger channel abstractions to empower developers to maintain code and create more polished interfaces.
Takeaway
In this episode we have learned:
If I had a magic wand…I would introduce a feature that allows configuring agents to drop pending work at shutdown;
If I had a magic wand…I would provide a “SObjectizer Lite” version tailored for real-time systems;
If I had a magic wand…I would strengthen telemetry data type by adding more information in order to simplify and make filtering more efficient;
If I had a magic wand…I would introduce a way to subscribe for a default message type;
If I had a magic wand…I would introduce stronger channel abstractions to empower developers to maintain code and create more polished interfaces;
As usual, calico is updated and tagged (even though this installment does not introduce any commit).
What’s next?
We’re nearing the end of the series, and it’s been quite a journey. I hope you found it interesting, even though some episodes may have been longer than intended due to my enthusiasm for the topic.
In the upcoming and final article – the Epilogue – we’ll conclude the series and offer suggestions for delving into more topics regarding SObjectizer.
After pairing with Ronnie, it became apparent that there is a need to delve into broader design considerations that could benefit inexperienced users of SObjectizer. This exploration might also be useful for designing message-passing styled applications in general.
Although the topic is vast, the goal here is to offer key insights and raise awareness about important aspects that have been relevant throughout my experience with SObjectizer over the years. This discussion aims to inspire new ideas and approaches to design applications using this paradigm.
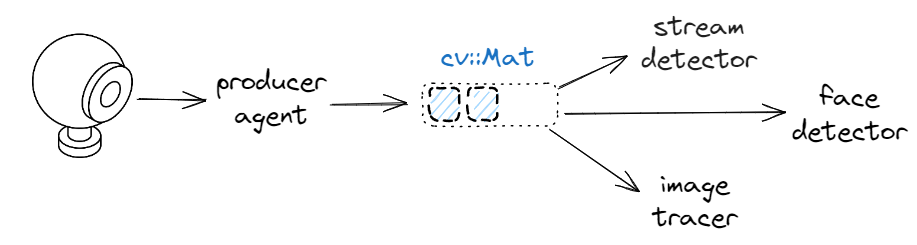
There is no “interface”
Agents within SObjectizer offer the flexibility to handle any message type without requiring a traditional public interface. For instance, an agent subscribing to a channel like main for messages of type cv::Mat doesn’t need to know about the sender, and vice versa. Agents operate akin to (theoretical) microservices, decoupled from one another and interacting solely through message exchange.
This model inherently promotes the Open/Closed Principle, as components can adapt to evolving business needs without internal modifications. For example, in projects like calico, rearranging agents can yield vastly different workflows to address diverse business requirements. Even in the absence of a particular component, it can be seamlessly integrated into the system without disrupting existing ones.
However, while not exposing an explicit interface, it doesn’t imply that agents can handle every possible message. The drawback here is that an agent’s “intent” is only explainable from its implementation details.
In essence, understanding which messages an agent can handle requires delving into its source code, often limited to functions like so_define_agent(). This contrasts with classical Object-Oriented Programming, where classes declare methods corresponding to the messages they handle. Moreover, Object-Oriented Programming further abstracts this aspect by introducing the concept of interface, which represents a list of methods that implementers guarantee to define. This distinction highlights unique considerations when designing systems with SObjectizer and with the actor model in general, as actors provide no interface at all.
The situation becomes more intricate when considering agent states. Indeed, agents not only process messages but also adapt their behavior based on their current state. Also, transitions between these states are not exposed at all.
Some actor model-based frameworks have tackled this common issue by introducing a “typed” actor concept, as seen in Akka. While SObjectizer doesn’t inherently include this concept, there have been initial efforts to explore whether SObjectizer users experience similar challenges and to propose a potential solution, as blogged in this initial draft (in Russian).
My personal experience with this issue is limited because my team and I usually have access to the source of agents. However, as a best practice, I tend to roughly document the “interface” of existing agents in the header files, as illustrated here below:
// handles [cv::Mat]
class image_tracer final : public so_5::agent_t
...
// handles [cv::Mat]
// outputs [cv::Mat]
class face_detector final : public so_5::agent_t
...
In more complex cases, I rely on common sense to ensure that the comments are clear and informative without becoming overly complicated.
Another important but often underestimated tool for documenting agents is unit and integration testing, as discussed in another article. Tests should be designed to identify and showcase both typical and edge cases, offering runnable code that can be beneficial for other developers.
Effective agent organization
One key aspect we’ve learned about agents is that they are always registered and deregistered within a cooperation. Essentially, this means that we cannot simply create an agent and inject it into the environment; instead, we must add it to a cooperation first. Once a cooperation is established and running, however, there is no built-in mechanism to add new agents to it. This design decision aligns with the transactional nature of cooperations. But, in many scenarios, dynamic creation of agents is a common requirement, necessitating the creation of new cooperations to host these agents.
A straightforward approach to manage dynamically created agents in SObjectizer is to introduce a new cooperation for each new agent. The SObjectizer environment offers a function called register_agent_as_coop() precisely for this purpose. Typically, it’s a good practice to organize these one-agent cooperations as children of larger cooperations that are relevant to the system. For instance, in a system like calico, we might dynamically create all agents as children of a larger cooperation designated for each camera. This organizational structure simplifies the process of deregistering all agents associated with a specific device, as they are grouped within the same cooperation. For example, if a camera is removed from the system, we can easily deallocate all the agents associated with it by deregistering the cooperation that represents the camera’s “group”.
Certainly, the same approach remains effective when multiple agents are logically part of the same cooperation. In such cases, we wouldn’t create individual cooperations for each agent but rather group them together within a single one. However, when we need to trigger deregistration for a single agent, as learnt in a previous post, opting for one cooperation per agent is usually preferred.
Another method we explored in the previous post involved organizing agents based on their functionality. For instance, we grouped all the “monitoring” agents into the same cooperation. In this case, we initially created all the involved agents statically at program startup, but the same can be achieved dynamically as discussed earlier.
An additional rationale for structuring cooperations in hierarchies is to facilitate the sharing and propagation of dispatchers. A recent update of SObjectizer includes new functionalities that allow access to both agent and cooperation dispatchers. This enhancement was prompted by feedback provided by a user and myself.
A compelling example is a workload distribution scheme featuring a root cooperation and several dynamically created worker agents. Typically, we create the cooperation with a specific binder and pass it to the root agent to generate workers accordingly. However, this approach not only adds boilerplate code but also fails to propagate to any children of the workers (again, we have to pass it explicitly). A cleaner solution is to leverage the new features introduced in SObjectizer 5.8.1:
so_this_coop_disp_binder() gets the binder of the agent’s cooperation;
so_this_agent_disp_binder() gets the binder of the agent.
Domain-specific abstractions on top of SObjectizer
When adopting SObjectizer, there are three possible scenarios to consider:
starting from scratch: this involves beginning a new project where SObjectizer is the chosen concurrency framework from the outset;
starting from a codebase without existing concurrency: in this scenario, there is no prior concurrency layer in the codebase, making the integration of SObjectizer per se relatively straightforward (the most complicated part is how to redesign the system for concurrency);
starting from a codebase with an existing concurrency layer: this scenario presents more complexity as there is already some concurrency code implemented using another library, whether it be a first-party or third-party solution.
In my case, I was in the third scenario as I had existing code based on PPL’s agents. I had previously encapsulated the existing library within a thin abstraction layer, which enabled me to work side-by-side without disrupting the existing codebase. The main task involved implementing another version of this layer, particularly to accommodate the addition of new “agents” specific to SObjectizer.
In essence, the new layer introduces an “agent manager” entity responsible for dynamically adding agents to the system. However, to better organize the interactions and accommodate the scenario similar to calico, where multiple cameras are involved, I decided to introduce an additional abstraction between the manager and its clients.
In this setup, clients interact with a “session” entity, which offers functionalities for introducing agents to the system. At the logic level, each session corresponds to a device. This is also beneficial for testing, as creating multiple sessions emulates using multiple devices.
But the real benefit of the session lies elsewhere: agents are not added randomly, instead, the session provides functions for adding agents to predefined logical groups (cooperations), such as “monitoring” or “high-priority”. Internally, these groups are bound to predetermined dispatchers but there is also the possibility to create new custom groups. All such groups are structured as children of a root cooperation corresponding – still at the logic level – to a specific device.
Additionally, the session facilitates the creation and referencing of message boxes and chains, streamlining the management process. It ensures that chains are automatically closed when the session is destroyed or when the environment is shut down.
Here below is a basic implementation of the agent manager, as a foundation for further development:
Here is a brief description of the main entities involved:
chain_holder, implemented using unique_ptr, acts as an RAII-wrapper ensuring the closure of the chain upon its destruction. It utilizes chain_closer to customize the closure mechanism of the chain;
agent_session_state includes the data utilized by an agent session, as elaborated later. In addition to the environment, a unique identifier, and a function object for message chain creation (which reenters agent manager), the session includes session_coops;
session_coops is a structure containing all “cooperation roots” currently available and their binders.
In essence, the agent manager:
creates and destroys sessions;
manages message chains.
In general, create_session() functions might take an extra parameter containing the “recipe” of the predefined cooperations (session_coops::group_to_coop) to include in the session. Here below is an incomplete implementation of agent_session:
In this example, there are no functions to create groups but, instead, the session provides domain-specific named functions for adding agents to existing groups. The available groups are added when the session is created by the manager.
At this point, there’s no need to access the environment directly, as each group already provides its own binders. Here’s the example from the previous post rewritten in terms of the agent manager and session:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
agent_manager manager;
auto session = manager.create_session("webcam");
const auto main_channel = session.get_channel("main");
const auto commands_channel = session.get_channel("commands");
const auto message_queue = session.make_chain();
const auto waitkey_out = session.get_channel(constants::waitkey_channel_name);
session.add_dedicated_thread_agent<image_producer>(main_channel, commands_channel);
session.add_dedicated_thread_agent<service_facade>();
session.add_monitoring_agent<image_tracer>(main_channel);
session.add_monitoring_agent<fps_estimator>(std::vector{ main_channel });
session.add_monitoring_agent<telemetry_agent>();
session.add_monitoring_agent<stream_heartbeat>(main_channel);
session.add_monitoring_agent<error_logger>(main_channel);
session.add_core_agent<remote_control>(commands_channel, message_queue);
auto resized = session.get_channel();
session.add_core_agent<image_resizer>(main_channel, resized, 0.5);
auto faces = session.get_channel();
session.add_core_agent<face_detector>(resized, faces);
session.add_core_agent<image_viewer>(faces, message_queue);
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
As you see, since we don’t return created agents from add_agent-like functions, there is no way to get output from such agents as before. For this reason, we opted for using explicitly created channels.
By the way, these are just open design ideas and are not intended to cover all the scenarios. A full implementation of this “layer” is provided in the latest version of calico.
Handling “any” message type
In SObjectizer, an agent can only subscribe for messages of an explicitly defined type:
It’s impossible to subscribe to a message type that hasn’t been specified. This differs from frameworks like CAF, where there is support for a default handler.
Why should we ever need this?
For example, in calico, suppose we add support for a new image type and we want image_tracer to handle it. We have two options to accommodate this change:
subscribe to this additional image type within the agent;
introduce a “converter” agent that converts the new image type into cv::Mat. Then, bind the output of this agent to the input of image_tracer using a channel.
However, a simpler approach could be to subscribe to a generic “unhandled” type, like so:
so_subscribe(channel).event([](so_5::<unhandled>) {
osyncstream(cout) << "got a new message\n";
});
This approach may not provide the exact functionality because image_tracer currently prints the size of the image (an information that wouldn’t exist in unhandled) and ignores non-image types. However, for troubleshooting purposes, it could be an acceptable trade-off. Evidently, this unhandled type does not exist in SObjectizer.
Another hypothetical solution proposed by Yauheni would involve leveraging inheritance to handle message types. In this approach, the event-handler searching procedure of SObjectizer would be modified. If an event handler for a specific type is not found, SObjectizer would then search for any handler of its base type:
class image_base : so_5::message_with_fallback_t {...};
class image_vendor_A : public image_base {...};
class image_vendor_B : public image_base {...};
...
void first_agent::so_define_agent() {
so_subscribe_self()
.event([this](mhood_t<image_vendor_A> cmd) {...})
.event([this](mhood_t<image_vendor_B> cmd) {...})
.event([this](mhood_t<image_base> cmd) {...})
...
}
void second_agent::so_define_agent() {
so_subscribe_self()
.event([this](mhood_t<image_base>) { ++m_counter; });
}
...
Here above, if second_agent receives an instance of image_vendor_B, the handler would be executed. However, we clarify again that this behavior is not supported at the moment and, likely, won’t be in the future.
Message proliferation
Another question related to the above-mentioned topic concerns the “fatness” of agents. Should an agent be responsible for handling a wide variety of messages, or is it preferable, whenever feasible, to limit its scope to specific types of messages? In general, there is a tendency to utilize the versatility of message handlers to efficiently manage multiple types within a single agent, however there are situations where supporting an excessive number of types can become cumbersome.
For example, in calico we have developed more than a dozen agents all handling cv::Mat only. What if we need to introduce and handle another image type? The first two options have been already discussed: either handle this new message type into all current agents or introduce a “converter” agent (or a message sink equipped with the new bind_and_transform()) that will be the only agent coupled with this new image type.
As usual, it depends. Some possible reasons to prefer handling the new type explicitly:
functionalities: the new type introduces functions and properties that we are required to use;
performance: the conversion incurs a cost we are not allowed to pay;
it’s not possible to do otherwise (e.g. the conversion is not possible).
However, if none of these conditions are met, opting for a conversion might be a more lightweight choice. In this case, a radical approach involves designing a “generic image type” that represents any possible image type within the system. Then, all agents would use this type instead of cv::Mat. This approach resembles the idea of “anywhere a constant string is required, use string_view“. In our scenario, this means designing a sort of “generic image type” that would be created from any image type within the system. However, this approach entails trade-offs, as there may be scenarios in the future where this generic type cannot effectively handle a new hypothetical type, or the cost of performing the creation is still not sustainable.
Finally, a hybrid approach could be adopted, where only specific agents use the new type when necessary. For instance, the image_tracer might log additional information, or the image_saver_worker might utilize native-type save operations.
Another aspect to consider is the dilemma of choosing between signals and messages. In principle, the absence of state distinguishes messages as signals. However, there are scenarios where additional data might be needed in the future. For instance, let’s say we need to add a timestamp to camera start and stop commands for storage purposes. Would the code handling these commands need to change to accommodate this new requirement?
In practice, the code handling signals is often designed to be resilient to such changes. This is because signals are handled using mhood_t<signal_type>, which continues to work seamlessly even if the signal evolves into a message. However, the reverse scenario is not true, as ordinary messages can be handled without wrapping the type into a mhood_t.
As discussed in previous articles, the most future-proof approach to handling types in SObjectizer is by using mhood_t. However, my personal preference is to break code if a message transitions to a signal, as this would likely indicate a significant change in the system’s behavior.
One agent per operation?
When designing service_facade, we initially chose to spawn “one agent per client,” with each agent subscribing to the client’s requests and managing gRPC streaming by writing images back to the client when available. While this approach is straightforward and works well for a small number of clients, it presents scalability challenges.
Firstly, we observed that having too many subscribers can impact performance, as the sending operation is influenced by the number of receivers. For example, sending an integer from an agent on a dedicated thread to 10,000 “no-op” agents in a thread pool with 4 threads takes approximately 2 milliseconds on my machine. While this delay might be negligible in some scenarios, it can become significant in others. Secondly, managing a large number of agents can become cumbersome in terms of debugging, profiling, and observability. Finally, there may be missed optimization opportunities. For instance, when multiple clients are subscribed to the same channel (that is very common in our use case), each service worker performs image compression to JPEG before sending. However, this results in redundant compression operations performed simultaneously by multiple agents, leading to inefficiency as the compression is typically a CPU-bound operation.
Hence, we often adopt an alternative approach where agents represent stages of a pipeline, minimizing agent proliferation. For example, an alternative implementation of the “calico service” could involve the following components:
only one agent is tasked with subscribing to channels on behalf of clients, maintaining a mapping of channels to clients;
another agent equipped with thread-safe handlers (or a group of multiple agents), handles the compression of frames from one channel and forwards the compressed results to the next stage;
another agent equipped with thread-safe handlers (or a group of multiple agents), is responsible for writing each compressed frame back to the specific client, ensuring the correct order of writes.
For agents responsible for steps 2 and 3, we may choose to utilize two different thread pools. For step 2, where compression of frames occurs, we should consider the guidelines for CPU-bound tasks. This means sizing the thread pool according to the number of available CPU cores (or slightly fewer to leave room for other system tasks, or +1 as others recommend). On the other hand, for step 3, which involves writing compressed frames back to specific clients, we should apply the guidelines for I/O-bound tasks. In this case, it’s beneficial to have more threads than the number of CPU cores to maximize CPU resource utilization during wait times for I/O operations.
While this approach shares similarities with Staged Event-Driven Architecture (SEDA), the flexibility inherent in SObjectizer enables us to overcome some of the challenges associated with that pattern, including thread pool management.
Takeaway
In this episode we have learned:
although agents provide significant flexibility, their lack of explicit interfaces can make it challenging to discern which messages they handle and in what state they operate;
organizing cooperations in hierarchies can help manage the system more effectively, such as deregistering a group of related agents;
creating a manager either tailored on specific needs or more generic to encapsulate SObjectizer functionality could be beneficial, particularly for simplifying the dynamic creation and management of agents;
SObjectizer does not permit subscriptions for unspecified types, meaning it’s not feasible to establish “default handlers” or similar mechanisms;
handling multiple message and signal types from an agent is common practice, but excessive type proliferation can become inconvenient. In such scenarios, opting for conversion to a common type or exploring hybrid approaches can be beneficial;
proliferation of agents often leads to scalability and observability issues; therefore, the preferred design strategy involves creating agents that represent stages of a processing pipeline, as in SEDA (Staged Event-Driven Architecture).
After a productive day of pair programming with Ronnie, as we head back home, we run into Dan, an experienced developer on our team, who is eager to share some feedback on SObjectizer.
In the next installment, we’ll delve into what Dan dislikes the most about the library and explore what he would change if he had a magic wand.
As emphasized throughout this series, one of the most significant advantages of the actor model abstraction is its inherent decoupling of agents from threads. This separation allows us to configure the binding of agents to threads using dispatchers, an essential decision that typically depends on the specific requirements of the scenario we’re addressing. This flexibility enables us to dynamically adjust the threading setup, even at runtime, without being tethered to the implementation details of the agents.
However, without clear guidelines or established patterns to follow, choosing the appropriate dispatchers can be a non-trivial decision. It seems Ronnie, a new member of our team, is encountering just this dilemma.
In this post, we would like to share a way to let dispatchers “emerge” from the system: suppose we bind all agents to the same thread leveraging the default one_thread dispatcher. Then we wonder for which agents this decision does not fit, why, and what alternative options are preferable. In this manner, like a sculptor removing material pieces to attain the desired form, we will selectively unbind agents from the shared thread, assigning to other dispatchers only those that would benefit from an alternative strategy.
The aim of this article is to highlight the importance of asking the right questions rather than seeking exact answers. This is because, as mentioned, the process of binding agents to dispatchers is heavily contingent upon the specific requirements of the system. These questions delve into various “dimensions” to consider when determining whether an agent should remain in the shared thread or if it’s more advantageous to bind it to another dispatcher. By understanding the pertinent questions to ask, we can facilitate the emergence of the optimal choice within the system.
Before diving into one of the longest posts of the series, we’d like to provide a concise list of considerations that we’ll explore further in this article. This quick reference guide will assist you in selecting dispatchers for your future projects.
Start by binding all agents to the same default dispatcher. Then, consider the following steps:
identify agents that require a dedicated thread, either because they cannot be blocked by others or because they cannot block others;
identify tasks that would benefit from parallelization, both CPU-bound and I/O-bound, and consider distributing them across multiple agents or a single agent with thread-safe handlers;
identify sequential pipelines and consider assigning all agents involved to the same thread;
determine if certain agents have higher priority in message handling;
consider any special context requirements for agents, such as executing logic on a specific or fixed thread;
for agents that can’t avoid sharing state, consider binding them to the same thread to avoid concurrency issues.
Single-threaded, when possible
When utilizing SObjectizer for the first time, we get exposed to its default dispatcher, known as one_thread, which assigns every agent to the same thread. While this dispatcher may appear trivial, our benchmark discussions have revealed that, put simply, inter-thread message exchange and context switching incur a cost. Practically speaking, if multiple agents have no benefit from concurrent execution, binding them all to the same thread is a valuable approach.
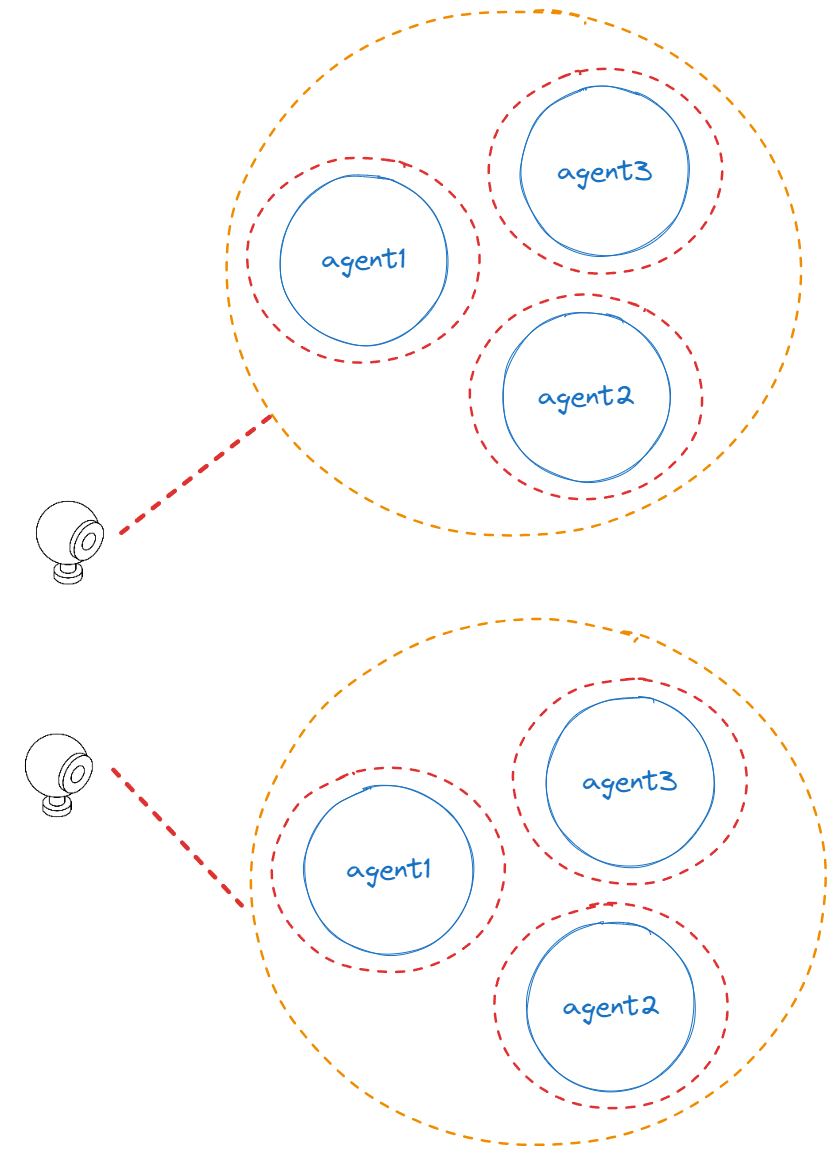
For example, in calico the data production depends on the frame rate of the device. With my laptop hosting a 30fps camera, this translates to approximately 33 milliseconds between two consecutive frames. Suppose we have this setup:
If stream_detector, image_tracer and face_detector process a single frame sequentially and the total time taken remains within 33 milliseconds on average, we could consider assigning them all to the same thread to guarantee a 30fps throughput. This will be equivalent to processing sequentially each frame by the individual agents.
While this observation may appear obvious, it highlights a first guideline: when binding agents to multiple threads is unnecessary or has negative consequences, opting for a single thread is a choice to consider.
Hence, if the aforementioned scenario remains unchanged, opting for a single thread could be a good choice. However, in software development, scenarios rarely remain static. For instance, we may eventually use a new camera that is 100 times faster than our current one, or we might introduce and combine other agents we have developed so far, such as the image_viewer or the image_saver.
Is a single thread still a good choice?
As we delve deeper into the complexities ahead, we’ll explore other dimensions to consider that we’ll discuss in the rest of the article. Speaking in general, there are some common traits that make agents good candidates to share their thread, such as:
“cheap” operations (e.g. message rerouting);
agents tolerant of delays in their reactions.
Here are some possible ideas applied to calico:
error_logger (tolerant of delays)
image_tracer (tolerant of delays)
fps_estimator (cheap operation)
maint_gui agents (only reroute messages)
stream_detector (cheap operation)
stream_heartbeat (cheap operation)
We assume, in this context, that writing to the console is a cheap operation, otherwise, we might introduce an agent solely responsible for console output. In addition, agents that are part of a “processing pipeline” (such as the “pipes and filters” and “routing slip” patterns we encountered in a previous post) are also good candidates. In fact, in the case of pipelines, the decision to employ individual agents (or groups) to operate simultaneously depends on its true effectiveness.
To block, or not to block
We now embark on exploring the first “dimension” to consider to determine whether certain agents should have on their own thread or not.
Let’s get back to the previously discussed scenario where all the agents share the same thread:
What about the producer agent?
In calico, we developed four image producers:
image_producer
image_producer_callback
image_producer_recursive
virtual_image_producer
Before discussing a possible answer, let’s first examine whether the “traits” for binding agents to the same thread discussed before align with our producers:
agents performing very “cheap” operations: only image_producer_callback;
agents tolerant of delays in their reactions: none, in general.
Assuming that starting the camera is a “cheap” operation (it is not, in general, but consider that it’s a mandatory operation we would await in any case to produce data), it seems that only image_producer_callback is a good candidate for sharing its thread with the other agents. Now, let’s get into the things.
To answer the question, we might consider the type of operations the producers perform, which might be either blocking or non-blocking.
Typically, we prefer employing non-blocking operations since these do not cause us to wait for the underlying operation to complete, and also offer the operating system the opportunity to utilize threads more efficiently. These operations include, for example, non-blocking I/O primitives, asynchronous function calls, and operations that use callbacks or futures for handling completion. Non-blocking functions are not black magic and sometimes require support from the operating system.
Waiting inevitably occurs somewhere in the system, but typically, we’re not directly exposed to it. For instance, consider image_producer_callback which does not wait for the next image to be retrieved from the device. Instead, a callback is automatically invoked by the underlying device when the next frame is ready. In this scenario, the producer does not engage in a blocking operation.
On the other hand, blocking operations – unsurprisingly – blocks until a certain resource becomes available – such as disk, network or synchronization primitives. Consider image_producer_recursive and virtual_image_producer: both of these agents perform a “blocking” operation every time they attempt to retrieve the next frame. Even worse, image_producer monopolizes its worker thread by executing a tight loop where the next frame is read on each iteration.
The primary consequence of an agent engaged in blocking operations is clear: if its thread is shared with others, they will be indirectly affected by the blocking operation. Therefore, if it’s imperative that such agents aren’t “blocked”, they should not share their thread with the blocking agent. To address this issue, usually we give the blocking agent a dedicated thread. Also, the opposite scenario is similar: if a certain agent mustn’t be blocked by others, it should have its own thread.
Then it seems we have a guideline: when an agent must not be disturbed by others, or when others should not be disturbed by the agent, opting for a dedicated thread could be a viable solution. Some good questions to ask are: “is it sustainable for the agent to be blocked?” or “is it sustainable that the agent blocks others?”.
While active_obj presents the most straightforward choice, a carefully adjusted thread pool is also a possible alternative. This choice depends on various factors, including the expected number of agents. For instance, in calico there are only a few dozen agents. Therefore, allocating a dedicated thread for each of them should be sustainable, considering also they don’t stress the CPU. However, as we discussed in a previous episode, having a large number of threads could swiftly jeopardize the system’s performance. Take, for example, a massively parallel web server scenario, where allocating a thread for each client, despite potentially involving blocking network operations, might be a risky choice. In such cases, employing a thread pool is typically the preferred alternative. We’ll elaborate this aspect a bit more in another section of this article.
It’s worth noting that while a blocking operation typically doesn’t directly relate to CPU usage, if multiple CPU-intensive operations are simultaneously running and some threads become “blocked” while awaiting their turn to execute instructions, we may also consider this a form of blocking.
To answer the initial question, we should determine which producers are allowed to “block” others and vice versa. A rough answer might be given as follows:
image_producer monopolizes its context then it wouldn’t leave others to handle any events. Thus, it must have its own thread;
image_producer_callback actually uses its thread only in response to start and stop signals (as the callback is invoked on the device’s worker thread). This means, it might share its thread with the other three agents involved in the system;
image_producer_recursive and virtual_image_producer block only when handling the grab_image signal.
It’s essential to emphasize the first point: if an agent monopolizes its context (e.g., if so_evt_start() contains an infinite loop), binding it to a dedicated thread is the only choice. Generally speaking, we say the agent does not work cooperatively as it never gets back control until deregistered. This stands as a general rule.
The last two producers warrant further discussion: while it may seem they should have their own thread, this decision hinges on the broader context of the system. As mentioned earlier, if the other agents operate within the expected throughput, allocating an additional thread for the producer may be unnecessary. Hence, the decision depends on factors such as the arrival rate of images, the impact of operations performed by the agents in the group, and the expected throughput. The advantage is that we have options and can fine-tune the system accordingly.
Finally, we discuss a potential issue with binding image_producer_callback to the same thread as other agents. As mentioned, we consider starting the camera as “cheap” because without starting the camera, the system is rendered useless. This is not true in general. Nonetheless, the crux of the matter lies elsewhere: in practice, after starting the acquisition, image_producer_callback only needs to handle the “stop acquisition” signal to halt the device. Suppose some of the agents experience some delay, leading to an event queue that looks like:
If a stop signal arrives, it will be enqueued at the end as a demand for image_producer_callback. This means, it will be processed after the other 6 demands currently in the queue. Maybe this is not an issue but in some cases it might be. At this point, another feature of SObjectizer is to consider: agent priorities. Essentially, this feature allows for the demands to be handled in different orders based on the priorities of agents. In this context, if we assign image_producer_callback a higher priority than others, the “stop signal” would be processed before the rest of the requests.
While assigning an agent a dedicated thread is the only means to prevent it from blocking others – and vice versa, the notion of “priority” presents another opportunity that can help us in avoiding dedicated threads when they’re not strictly necessary.
In the next section, we’ll learn more about this dimension to consider.
Priority-based considerations
The example presented above is not an isolated case. There are scenarios where multiple agents can share a thread as long as their “priority” influences the order of processing demands in the queue. In essence, every agent can be optionally marked with a certain priority:
class my_agent : public so_5::agent_t
{
public :
my_agent(context_t ctx)
: so_5::agent_t( ctx + so_5::priority_t::p3 )
// ...
};
Priorities are enumerations of type priority_t and span from p0 (the lowest) to p7 (the highest). By default, an agent has the lowest priority (p0). In general, the priority is an implementation detail of the agent. SObjectizer provides three dispatchers that take priorities into account when processing demands:
prio_one_thread::strictly_ordered
prio_one_thread::quote_round_robin
prio_dedicated_threads::one_per_prio
The distinction between the “one thread” and “dedicated thread” concepts essentially boils down to the following: in the former scenario, where all events are processed on the same shared thread, the dispatcher can strictly order the demands based on the higher priority of agents. Conversely, in the latter scenario, one distinct thread is allocated for each priority.
This feature offers another perspective to determine how to bind agents to dispatchers and offers the opportunity to fine-tune the system based on the relative importance of agents or to partition the binding of agents to threads according to priority.
As mentioned before, for instance, we could consider assigning a higher priority to image_producer_callback compared to the other agents in the group. Then we can bind them all to a strictly_ordered dispatcher that operates intuitively: it manages only one shared thread and its event queue functions like a priority queue, ensuring that events directed to higher priority agents (the producer) are processed ahead of those directed to lower priority agents (image_tracer and face_detector). This way, if the stop signal arrives while the event queue already contains other demands, it will be processed before the others. Here is an example:
// ... as before
calico::producers::image_producer_callback::image_producer_callback(so_5::agent_context_t ctx, so_5::mbox_t channel, so_5::mbox_t commands)
: agent_t(std::move(ctx) + so_5::priority_t::p1), m_channel(std::move(channel)), m_commands(std::move(commands))
{
}
// ... as before
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(disp::prio_one_thread::strictly_ordered::make_dispatcher(env.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer_callback>(main_channel, commands_channel);
c.make_agent<stream_detector>(mbox);
c.make_agent<image_tracer>(mbox);
c.make_agent<face_detector>(mbox);
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
Another classic example involves a pair of agents: one tasked with processing operations and the other responsible for handling a “new configuration” command. In this scenario, when the “new configuration” command is received, it’s essential to handle it promptly. A priority schema is well-suited to address this requirement.
While this mechanism is effective in many cases, there are scenarios where one or more agents experience starvation, as high priority agents might jeopardize the working thread. For example, suppose we also mark image_producer_recursive with higher priority than other agents. We recall that image_producer_recursive always sends a message to itself after sending the current frame to the output channel:
This implies that assigning the agent a higher priority and binding it to a strictly_ordered dispatcher alongside other agents will prevent other demands from being processed! The producer would monopolize the event queue.
In this scenario, another potential solution is provided by prio_one_thread::quote_round_robin, which operates on a round-robin principle: it permits specifying the maximum count of events to be processed consecutively for the specified priority. Once this count of events has been processed, the dispatcher switches to handling events of lower priority, even if there are still higher-priority events remaining. This way, we might still give image_producer_recursive a higher priority than others but we can limit its demands to – let’s say – 1.
Another example where this dispatcher is useful is one where we manage clients with different tiers on service quality, such as the API subscription to a certain service. For example, tier-1 (or “premium”) clients require first-class quality of service, while others may have lower demands for service quality. By assigning a high priority to agents handling premium client requests and specifying a large quote for that priority, more requests from premium clients will be handled promptly. Meanwhile, agents with lower priority and a smaller quote will address requests from other clients, ensuring a balanced processing of requests across all client types.
Finally, an additional strategy is given by prio_dedicated_threads::one_per_prio which creates and manages a dedicated thread for each priority. For example, events assigned to agents with priority p7 will be processed on a separate thread from events assigned to agents with, for instance, priority p6. Events inside the same priority are handled in chronological order.
This dispatcher provides the capability to allocate threads based on priority. For instance, in a particular scenario, we might assign a certain priority to troubleshooting or diagnostics agents like image_tracer or stream_heartbeat, while assigning a different priority to “core” agents like face_detector and image_resizer. It’s important to note that priorities are implementation details of agents, meaning the only way to inject priority to an agent from outside is by taking a parameter that represents the priority in the agent’s constructor. For example:
Thus, unlike binding agents to dispatchers, priorities are not inherently separated from agent implementation details. However, we can still inject priority from outside if we create the agent “by hand”, (when the agent accepts agent_context_t in the constructor):
auto agent = make_unique<my_agent>(agent_context_t{env} + priority_t::p2, ...);
This way, when utilizing third-party or unmodifiable agents, incorporating priorities into existing agents is feasible.
In conclusion, priorities provide an additional dimension to consider when aiming to minimize the number of threads or when binding agents to threads might be based on priority. Some examples of good questions to ask here are: “is there any agent in the group requiring more special than others in terms of responsiveness?” or “could we assign agents to threads based on some fixed partition schema (such as assigning a sort of label to each agent)?”.
However, there are situations where binding an agent to a shared thread does not inherently pose an issue, but rather, distributing its workload across multiple threads presents an opportunity. For example, serving multiple clients of our gRPC service in parallel.
In the next section, we’ll share some thoughts about this essential dimension.
Using multiple threads
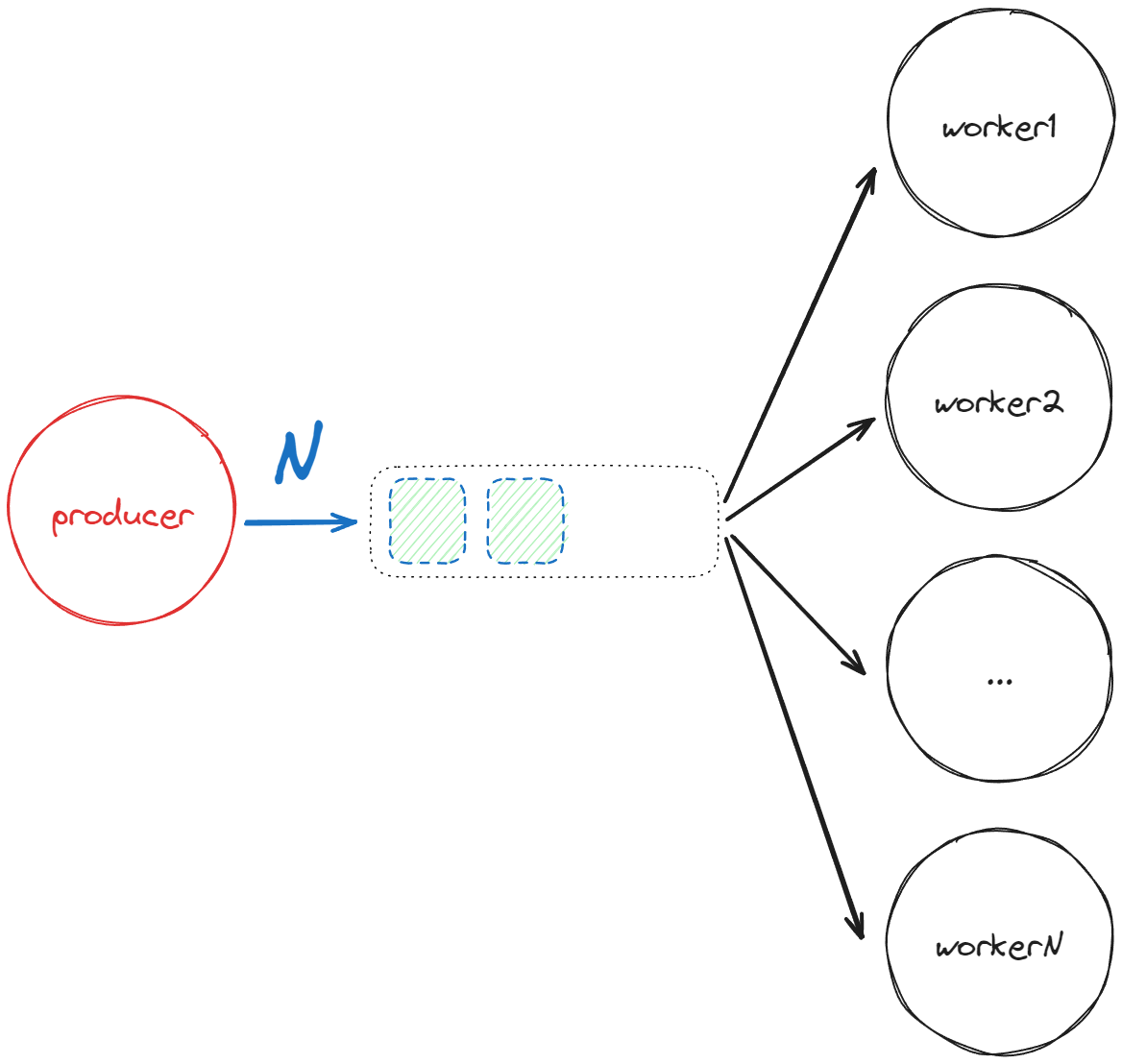
There are scenarios where breaking down a specific task into multiple parallel executions offers tangible benefits. A classic example is the “Scatter-Gather” pattern, where an operation is divided into subtasks that are concurrently executed by multiple workers, and their results are combined for further use. Similarly, in other cases, several coarse-grained operations are simply executed in parallel by independent workers. For instance, in our gRPC service, we spawn an agent to manage each client’s conversation.
Discussing SObjectizer, we’ve discovered various tools for distributing work across multiple workers. These options range from independent agents receiving messages from a message chain to a single agent with thread-safe handlers, and even more complex solutions involving a “task coordinator”.
We typically resort to dispatchers like thread_pool or adv_thread_pool, with a proper dimension. Specifically, we use adv_thread_pool when leverage thread_safe handlers is necessary.
Alternatively, as seen with image_saver, we spawn a fixed number of agents each bound to a dedicated thread using active_obj. Usually, a thread pool provides greater flexibility and options for fine-tuning, but the same considerations discussed earlier regarding the advantages of a dedicated thread per agent remain relevant.
The considerations we share in this section are for choosing the dimension of the pools, depending on the different scenarios we are facing. Determining the appropriate size for thread pools is more of an art than a science, but it’s essential to avoid extremes such as being overly large or too small. A thread pool that is too large may lead to threads competing for limited CPU and memory resources, resulting in increased memory usage and potential resource exhaustion. Conversely, a pool that is too small can impact throughput, as processors remain underutilized despite available tasks to be executed. Striking the right balance is key to optimizing performance and resource utilization.
Clearly, this is a broad and complex topic, and this post merely scratches the surface.
First of all, we should distinguish between CPU-bound and I/O bound tasks. Computationally intensive tasks, such as complex mathematical calculations, are considered CPU-bound, while operations that require waiting for external processes, like network requests, fall under the category of I/O-bound tasks. In such scenarios, efficient CPU utilization entails the ability to switch to other threads during periods of waiting, optimizing the use of available computational resources.
Usually, thread pools designated for CPU-bound tasks are sized to match the number of available CPU cores number_of_cores or a number close to that (+1, -1 or -2).
On the other hand, for I/O-bound operations, having more threads than the number of CPU cores is advantageous. This surplus allows for continuous activity on the CPU cores, even when some threads are blocked waiting for I/O operations. With additional threads available, new operations can be initiated, maximizing CPU resource utilization. This overlap in I/O tasks prevents idle time and optimizes the execution of I/O-bound tasks.
number_of_cpus is the number of available CPUs (e.g. cores);
target_cpu_util represents the wanted CPU utilization, between 0 and 1 (inclusive);
wait_time is the time spent waiting for IO bound tasks to complete (e.g. awaiting gRPC response);
service_time is the actual time spent doing the operation.
The ratio of waiting time to service time, commonly referred to as the blocking coefficient, represents the proportion of time spent awaiting the completion of I/O operations compared to the time spent on doing work. If a task is CPU-bound, that coefficient is close to 0 and having more threads than available cores is not advantageous. The target_cpu_util parameter serves as a means to maintain the formula’s generality, particularly in scenarios involving multiple thread pools. For example, if there are two pools we might set the target_cpu_util value to 0.5 to balance the utilization on both.
The blocking coefficient must be estimated, which doesn’t need to be precise and can be obtained through profiling or instrumentation. However, there are some other cases where finding a suitable pool size is simpler and doesn’t require applying the formula above.
A first scenario is like those encountered in calico, where interfacing with external hardware devices is necessary. In such cases, a common approach involves dedicating a separate thread for each device. For instance, if calico managed multiple cameras using “blocking” APIs, we might dedicate a thread for each camera to ensure efficient handling of device interactions.
Another pertinent consideration, not confined to the aforementioned scenario, arises when tasks depend on pooled resources such as driver connections, such as databases. In this case, the size of the thread pool is constrained by the size of the connection pool. For example, does it make sense to have 1000 active threads when the database connection pool can only accommodate 100 connections? Probably not.
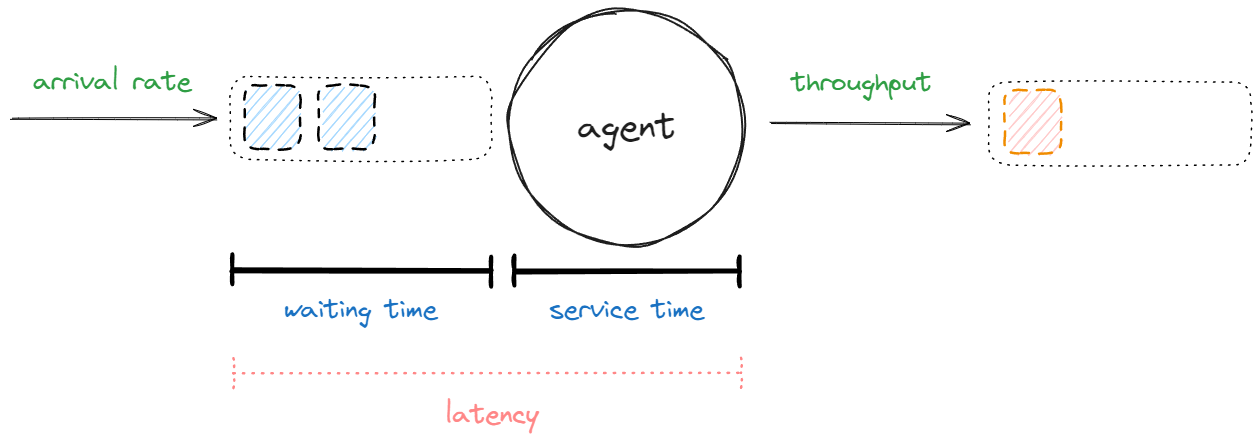
Finally, there are scenarios where we are required to estimate the number of workers given the target throughput. In other words, we should understand how the number of parallel workers influences latency and throughput. Little’s law can provide insight into this topic. It states that the number of requests in a system is equal to the arrival rate multiplied by the average time taken to service a request. By applying this formula, we can determine the optimal number of parallel workers required to manage a predetermined throughput at a specific latency level. The formula is here below:
L = λ * W
Where:
L is the number of requests to process simultaneously;
λ is the arrival rate (number of incoming tasks per time unit – e.g. 20fps);
W is the latency, or the average time taken to process a single request (e.g. 0.5s).
For example, if we consider a scenario where each operation requires 500 millisecond to complete (W), with a desired throughput of 20 fps (λ), we would need a thread pool with at least L = λ*W = 10 threads to handle this workload effectively. This formula can also serve to calculate the maximum throughput given the number of workers and average latency. Consider that SObjectizer’s telemetry capabilities discussed in the previous article might be helpful to estimate W.
In conclusion, when we have CPU-bound or I/O-bound operations that benefit from parallelization, we might consider thread pools or dedicated threads. Good questions to answer here are: “is the agent performing CPU-bound or I/O-bound tasks?” or “if throughput is an issue, is it feasible and beneficial to distribute work?”.
The next two sections explore a few additional scenarios that arose from a private conversation with Yauheni.
Sharing thread enables sharing data
Binding agents to the same thread brings another opportunity that was mentioned by Yauheni:
“It’s not a good thing in the Actor Model, but it’s the real life and sometimes we have to hold references to some shared mutable data in several agents. To simplify management of this shared data we can bind all those agents to the same worker thread”.
My initial assumption was that when adopting the actor model, we generally aim to minimize shared state as much as possible. However, as discussed in earlier posts, there are scenarios where shared state is unavoidable or hard to remove. In such cases, SObjectizer offers features to facilitate the effective management of shared state. I’m not suggesting that you take this matter lightly, but rather emphasizing that if avoidance is truly impractical, I share that SObjectizer provides tools to simplify the process and to make shared state more manageable.
In this regard, we can bind agents that share a common state to the same thread by utilizing dispatchers like one_thread, active_group, or a thread pool with cooperation FIFO. SObjectizer ensures that these agents will never be scheduled simultaneously, thereby guaranteeing the integrity of shared state management without necessitating locks nor atomics. The reason is clear: since all the agents involved run on the very same thread, there is no chance to access shared resources from different threads.
Consider our “routing slip” or “pipes and filters” pipelines. If the agents involved need to share data, leveraging the shared thread could be a suitable approach.
Special context requirements
Once again, Yauheni shared a valuable piece of his extensive experience:
“Some actions might need to be taken from a specific thread. For example, drawing to screen can be done from the main thread only. So we have to bind several agents to a dispatcher that schedules them on the right thread”.
In this case, it’s possible that we need to craft and use a custom dispatcher for the purpose. This might be not an easy task in general but we know where to start as we learnt in this previous post. For example, in calico we have discussed and crafted a do_gui_message_loop() function to guarantee the OpenCV drawing happens on the calling thread – and we call this function from the main thread. An alternative solution consists in developing a customized dispatcher. Just to share another example, SObjectizer’s companion project so5extra, provides some battle-tested dispatchers tailored for boost ASIO.
Yauheni also shared an additional scenario:
“Some 3rd party libraries must be used from one thread only. For example, a library may require calls like lib_init/lib_deinit to be performed from the same thread. Sometimes other calls from the library should be taken from the same thread too (because the library uses thread local variables under the hood). This requires us to bind agents to one_thread or active_group dispatcher”.
Since there isn’t a strict requirement for a specific thread to be utilized, but rather for certain operations to be executed on the same thread, there’s no necessity for us to develop our own dispatcher. As Yauheni suggested, we can leverage existing options such as one_thread or active_group dispatchers to fulfill this requirement.
A complete example
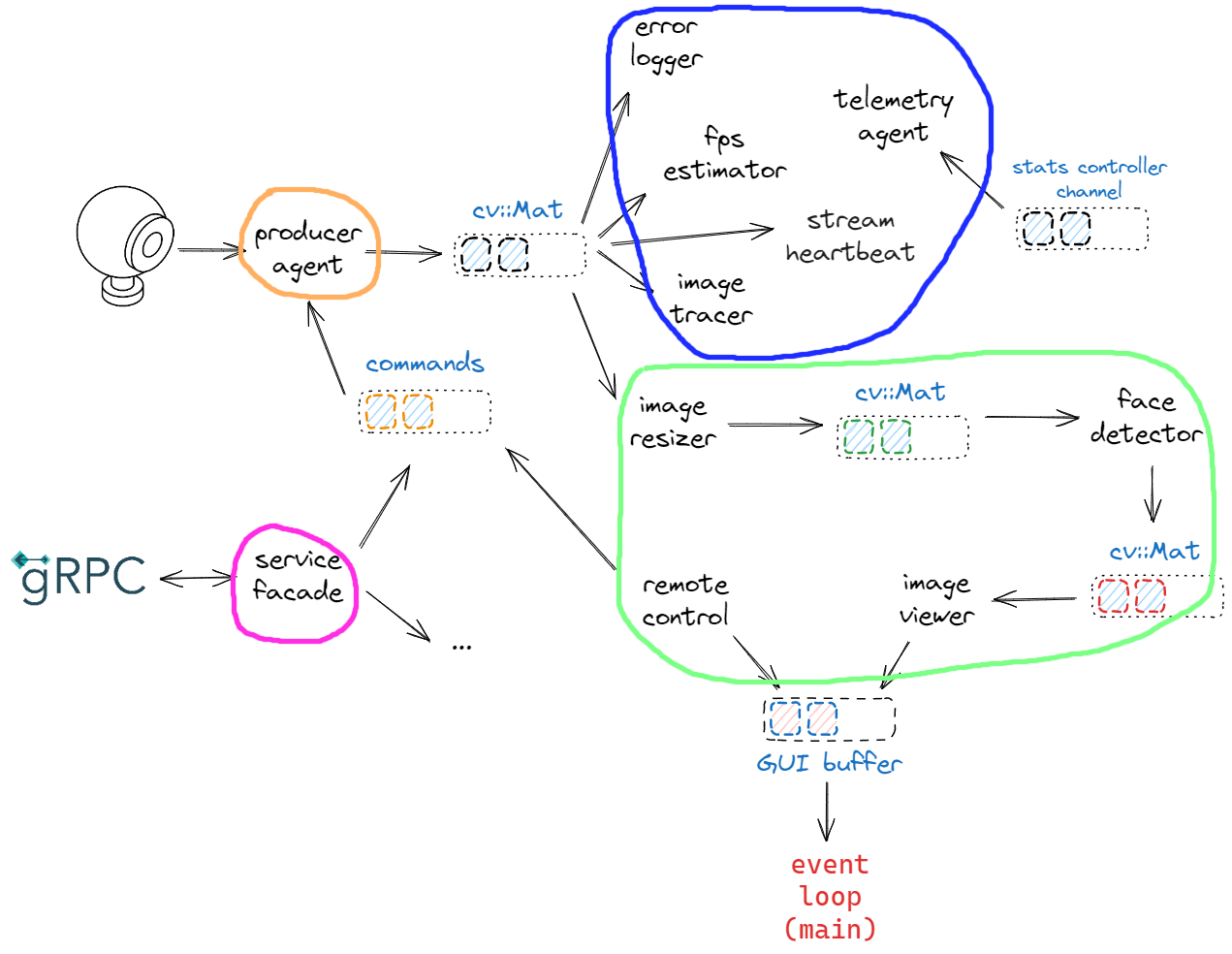
Before concluding, we apply some of the ideas discussed above to calico. We propose to set up the program as follows:
In essence:
a producer agent – suppose it’s the “blocking” one – sends images to the named “main” channel and gets commands from the named “commands” channel;
a remote_control gets command from the “UI”;
a service_facade enables external client to interact with the program;
“main” channel is subscribed by a bunch of agents that boil down as follows:
a “core” path that pass through an image_resizer that feeds a face_detector whose output is visualized to the screen using image_viewer;
a “support” path where image_tracer, fps_estimator, stream_heartbeat and error_logger contribute to monitor the system;
a telemetry_agent is also installed to display some telemetry data on demand;
the usual event loop from main handles the GUI messages.
We start with binding all the agents to the same the thread:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_channel("main");
const auto commands_channel = sobjectizer.environment().create_channel("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
const auto waitkey_out = sobjectizer.environment().create_mbox(constants::waitkey_channel_name);
sobjectizer.environment().introduce_coop([&](coop_t& c) {
c.make_agent<image_producer>(main_channel, commands_channel);
c.make_agent<remote_control>(commands_channel, message_queue);
c.make_agent<service_facade>();
c.make_agent<image_tracer>(main_channel);
c.make_agent<fps_estimator>(std::vector{ main_channel });
c.make_agent<telemetry_agent>();
c.make_agent<stream_heartbeat>(main_channel);
c.make_agent<error_logger>(main_channel);
const auto faces = c.make_agent<face_detector>(c.make_agent<image_resizer>(main_channel, 0.5)->output())->output();
c.make_agent<image_viewer>(faces, message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
At this point, we proceed with the “rebinding” phase.
The first question we typically ask is “which agent shouldn’t be blocked by others and vice versa?”. We identify two agents:
image_producer, since it blocks its thread all the time, we have no other choice;
service_facade, since starting and stopping the server might block, we decide to give it a dedicated thread.
The picture changes slightly:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_channel("main");
const auto commands_channel = sobjectizer.environment().create_channel("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
const auto waitkey_out = sobjectizer.environment().create_channel(constants::waitkey_channel_name);
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer>(main_channel, commands_channel);
c.make_agent<service_facade>();
});
sobjectizer.environment().introduce_coop([&](coop_t& c) {
c.make_agent<remote_control>(commands_channel, waitkey_out, message_queue);
c.make_agent<image_tracer>(main_channel);
c.make_agent<fps_estimator>(std::vector{ main_channel });
c.make_agent<telemetry_agent>();
c.make_agent<stream_heartbeat>(main_channel);
c.make_agent<error_logger>(main_channel);
const auto faces = c.make_agent<face_detector>(c.make_agent<image_resizer>(main_channel, 0.5)->output())->output();
c.make_agent<image_viewer>(faces, message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
Now, from the remaining agents, we speculate about which ones are “cheap” or might be tolerant to delays:
remote_control reroutes messages;
image_tracer prints to the console and, in general, is a “monitoring” agent;
fps_estimator is cheap, reacts to periodic events, and is a “monitoring” agent;
telemetry_agent reacts to slow rate events and is a “monitoring” agent;
stream_heartbeat reacts to slow rate events and is a “monitoring” agent;
error_logger prints to the console and should react to sporadic events;
image_resizer is CPU-bound;
face_detector is CPU-bound;
image_viewer reroutes messages;
Here are a few observations:
with the term “monitoring” agent we mean that, in this context, the agent doesn’t perform any “core” operations and may tolerate some delays;
we assume these agents don’t execute “blocking” operations, although writing to the console could potentially block;
the error_logger currently lacks the logic to send an alert in case of catastrophic failures or the reception of several errors in quick succession. While it may be acceptable for it to experience delays in our scenario, it might need to be more responsive in general.
Considering these factors, it appears that we can group all of these agents together into a kind of “monitoring” cooperation. However, we would exclude remote_control from this group since it represents a crucial part of the core business. Indeed, separating monitoring agents from others offers convenience, especially if we need to deallocate all of them together:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_channel("main");
const auto commands_channel = sobjectizer.environment().create_channel("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
const auto waitkey_out = sobjectizer.environment().create_channel(constants::waitkey_channel_name);
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(env.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer>(main_channel, commands_channel);
c.make_agent<service_facade>();
});
sobjectizer.environment().introduce_coop(disp::active_group::make_dispatcher(sobjectizer.environment()).binder("monitoring"), [&](coop_t& c) {
c.make_agent<image_tracer>(main_channel);
c.make_agent<fps_estimator>(std::vector{ main_channel });
c.make_agent<telemetry_agent>();
c.make_agent<stream_heartbeat>(main_channel);
c.make_agent<error_logger>(main_channel);
});
sobjectizer.environment().introduce_coop([&](coop_t& c) {
c.make_agent<remote_control>(commands_channel, waitkey_out, message_queue);
const auto faces = c.make_agent<face_detector>(
c.make_agent<image_resizer>(main_channel, 0.5)->output()
)->output();
c.make_agent<image_viewer>(faces, message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, waitkey_out);
}
Here is a picture of the different thread allocations:
The remaining agents might be bound to another active_group dispatcher or left with the one_thread dispatcher. Note that the core part of the system consists of the (sequential) pipeline:
image_resizer
face_detector
image_viewer
An alternative option would be to allocate a dedicated thread for this pipeline, particularly if there are multiple pipelines in the system. As the system expands and additional pipelines are introduced, it may be advantageous to assign all of them to a thread pool, which can manage threads more efficiently. Additionally, when managing multiple pipelines with varying service requirements, it’s convenient to consider agent priorities.
Finally, let’s review service_facade, which internally utilizes a thread pool. Specifically, each subscribe_client_agent is associated with a common thread pool of 4 threads. This aspect is worth some discussion. Firstly, given that the gRPC synchronous API is pooled, we may want to limit the number of threads to match the size of the library’s pool. By default, gRPC creates a thread for each CPU core and dynamically adjusts the thread count based on workload. We can configure this behavior to some extent and align our thread pool accordingly.
Another approach to sizing the pool involves applying Little’s law to approximate the number of workers needed to achieve a target throughput. To estimate latency, we can enable telemetry on the thread pool and observe thread activity under different workloads. For example, when subscribing to the gRPC service from 8 clients using a pool of 4 threads, the average latency per thread is approximately 5 milliseconds. This implies that to maintain a throughput of 500 requests per second, we should size the pool with 25 workers. However, this value should be adjusted to accommodate gRPC’s thread pool size, and then some other tests should be performed.
It was a long journey but we hope to have shared some useful ideas and good questions to ask when it’s time to select dispatchers.
The series is nearing its conclusion, and in the next post, we’ll delve into some design considerations and share additional ideas to assist you in designing SObjectizer-based systems more effectively.
Takeaway
In this episode we have learned:
dispatcher binding is a crucial decision when designing SObjectizer-based systems and actor model applications in general;
by default, SObjectizer binds all agents to the same thread, but it’s essential to consider alternatives based on specific requirements;
a method for determining dispatcher selection involves asking questions about agent traits and system requirements;
the first question concerns potential blocking: could an agent be blocked by others, or vice versa? If not, a dedicated thread may be necessary;
the second question relates to agent priorities: can a priority schema help avoid unnecessary thread allocation? Assigning priorities to agents and using corresponding dispatchers may be beneficial;
the third question addresses workload distribution: is the agent CPU-bound or I/O bound? Depending on the answer, distributing tasks across multiple threads or using thread pools can enhance system throughput;
lastly, it’s worth considering additional dimensions such as shared state management and constraining execution to specific threads. Shared state can be managed using shared threads, while constraints on execution threads can be addressed with custom dispatchers or those allocating only one thread, like one_thread and active_group;
by considering these “dimensions”, developers can make informed decisions about dispatcher binding and optimize the performance of their SObjectizer-based systems.
After spending some time we Ronnie, we realize there are other important considerations to share about designing systems with SObejctizer and some general ideas that holds for any applications developed using the actor model and messaging.
In the next post, we’ll delve into these topics further.
SObjectizer features a basic mechanism for gathering and distributing runtime telemetry data regarding its internals, such as the number of registered cooperations, the quantity of delayed or periodic messages, the length of event queues, the time spent processing events for each handler, and so on.
This feature is essential for getting insights into the performance and health of our applications at runtime, avoiding the necessity to develop our own monitoring system.
Following up our recent discussion about performance metrics, Helen is back with her discoveries about this feature of SObjectizer that is called Runtime monitoring. In this article we’ll learn how to use this tool effectively and we’ll apply it to calico.
Runtime monitoring in a nutshell
Runtime monitoring is seamlessly integrated into SObjectizer through conventional mechanisms: message passing and subscriptions.
Essentially, when the feature is enabled, SObjectizer automatically generates certain data sources that observe specific internal aspects of SObjectizer and generate corresponding metrics. For example, there is a data source for counting the number of cooperations registered within the environment. These data sources transmit their information to a dedicated component of the telemetry system known as the stats controller. The stats controller manages the activation and deactivation of telemetry data collection and distribution. When the telemetry is enabled, the stats controller runs in a separate thread. To distribute data, the stats controller grants access to a specialized message box that operates in the standard manner via subscriptions. It’s worth noting that telemetry samples are not continuously distributed; instead, the distribution period can be configured, as we’ll see in a moment.
Practically speaking, to collect telemetry data, we must explicitly turn on the stats controller and, optionally, set a distribution period – otherwise the default value is 2 seconds.
The stats controller is accessed through the environment:
// turn on telemetry
so_environment().stats_controller().turn_on();
// send telemetry data every second
so_environment().stats_controller().set_distribution_period(1s);
Since these options can be changed anytime, we introduce an agent that enables or disables telemetry collection depending on the current state, when a specific command is received (e.g. pressing t):
struct enable_telemetry_command final : so_5::signal_t {};
class telemetry_agent final : public so_5::agent_t
{
public:
telemetry_agent(so_5::agent_context_t ctx)
: agent_t(ctx), m_commands(so_environment().create_mbox("commands"))
{
}
void so_define_agent() override
{
st_turned_off.event(m_commands, [this](so_5::mhood_t<enable_telemetry_command>) {
so_environment().stats_controller().turn_on();
so_environment().stats_controller().set_distribution_period(1s);
st_turned_on.activate();
});
st_turned_on.event(m_commands, [this](so_5::mhood_t<enable_telemetry_command>) {
so_environment().stats_controller().turn_off();
st_turned_off.activate();
});
st_turned_off.activate();
}
private:
state_t st_turned_on{ this }, st_turned_off{ this };
so_5::mbox_t m_commands;
};
At this point, we are ready to subscribe for telemetry data.
How to subscribe for telemetry data
Runtime telemetry is delivered as messages defined into the namespace stats::messages. In particular, this namespace defines a message type representing a generic quantity of data:
stats::messages::quantity<T>
This message type is intended to convey information regarding quantities of a certain telemetry entity, such as the number of working threads for a dispatcher or the quantity of registered cooperations. In essence, when subscribing for telemetry data, we will receive a quantity<T>.
You might expect that T represents the type of telemetry information we are interested in. After all, one of the key advantages of SObjectizer is “message pattern matching”. However, T solely denotes the “unit type” associated with such a quantity, such as size_t. For instance, to obtain information about the number of working threads for a dispatcher, we receive a quantity<size_t>. This type is essentially hardcoded, indicating the type of data being transmitted, and should be retrieved by the documentation. At the time of writing, the only unit type available is size_t.
At this point, you might wonder how to differentiate between various telemetry types, like the count of registered cooperations and the number of working threads for a dispatcher, if they both arrive as quantity<size_t>. The answer lies in the quantity type itself: it includes not only the numerical “value” of the quantity but also carries information about the datasource that generated it.
In particular, data sources have unique names, each consisting of two strings:
a prefix, indicating a “group” of related data sources;
a suffix, indicating the specific data source of the group which produced the quantity.
For example, here below:
mbox_repository/named_mbox.count
mbox_repository is the prefix, whereas /named_mbox.count is the suffix.
Prefixes could be considered “dynamic” in nature, indicating that they may reference entities generated at runtime. For instance, consider these two distinct prefixes identifying two different one_thread dispatchers:
disp/ot/DEFAULT
disp/ot/0x3be520
0x3be520 uniquely identifies a particular dispatcher and can only be generated – then referenced – at runtime.
Conversely, suffixes are “fixed” strings, signifying that they pertain to predetermined categories of information within SObjectizer. For example:
/agent.count
/demands.count
/named_mbox.count
Therefore, when receiving a quantity<T>, we might filter the “type” of information by examining its prefix and suffix. To simplify this process, SObjectizer furnishes all “predefined” prefixes and suffixes in stats::prefixes and stats::suffixes namespaces.
Although prefixes for dispatcher-related information are not supplied since they are dynamic, the rules regulating their generation are rather straightforward:
every prefix starts with disp;
then it follows an abbreviated form based on the specific dispatcher, such as:
/ot — for one_thread dispatcher;
/ao — for active_obj dispatcher;
/ag — for active_group dispatcher;
/tp — for thread_pool dispatcher;
/atp — for adv_thread_pool dispatcher;
finally, the last part is a unique identification for a dispatcher instance that typically includes the dispatcher name (when specified) or an hex representation of the address of the dispatcher object.
It’s worth noting that all standard dispatcher factories (e.g. make_dispatcher()) accept a parameter to specify the name of the dispatcher.
Now, suppose we enhance our telemetry_agent to record statistics concerning our active_obj dispatcher, which is bound to the majority of our agents. Hence, we should subscribe to the stats_controller‘s message box and then we should only consider quantities of a specified active_obj dispatcher. First of all, we add a name to the dispatcher when we create the cooperation:
sobjectizer.environment().introduce_coop(
so_5::disp::active_obj::make_dispatcher(sobjectizer.environment(), "calico_active_object").binder(), [&](so_5::coop_t& c) {
// ...
});
Then, we install a delivery filter to discard any other telemetry data (one motivation for introducing delivery filters in SObjectizer was to facilitate discarding of uninteresting telemetry quantities):
We opted for wrapping the prefix into a string_view since SObjectizer provides prefix and suffix as raw char pointers. Update: SObjectizer 5.8.2 provides a function as_string_view() for both prefix_t and suffix_t. Finally, we add the subscription:
Another common way to filter quantities involves the suffix, allowing retrieval of data from all sources that produce a specific category of telemetry information. For instance, suppose we monitor the queue size of each dispatcher (the number of events awaiting processing). The suffix to verify against can be located in stats::suffixes::work_thread_queue_size():
Note that if we install multiple filters, only the last one is taken. Thus, to get /ao/calico_active_object OR any information about queue sizes, we might merge the two conditions as follows:
Monitoring the queue size of each dispatcher is a significant metric to detect potential bottlenecks, akin to assessing throughput, as discussed in the initial post about performance. Especially noteworthy is the potential need for further investigation if the queue size shows a gradual increase over time.
The complete list of all available suffixes and prefixes is published on the official documentation. We recommend referring to it to explore the additional telemetry data provided by SObjectizer.
Identifying start and end of each telemetry batch
You may have observed that the telemetry_agent receives one quantity for each telemetry data sent from the data sources. Then we typically set up some filters to refine the data to suit our specific interests. For example, suppose we have this setup of calico:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(sobjectizer.environment(), "calico_active_object").binder(), [&](coop_t& c) {
c.make_agent<image_producer_recursive>(main_channel, commands_channel);
c.make_agent<maint_gui::remote_control>(commands_channel, message_queue);
c.make_agent<telemetry_agent>();
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
Once the program is started and the ‘t‘ key is pressed in the remote_control window, logs similar to the following begin to appear:
Every line is a different quantity delivered to the telemetry_agent that passes through our filter. Thus, the corresponding message handler will be called 5 times. Nothing unexpected here.
Essentially, the stats controller generates a telemetry “batch” (called also “cycle” or “period”) occurring every second (as we configured before). At this point, it might be convenient to identify when a single batch starts and finishes, perhaps to enhance the clarity of the log. SObjectizer provides the necessary components to accomplish this task in an effective way. Specifically, the stats controller dispatches two “status” messages: one before sending the first quantity and another after dispatching the last quantity of each batch:
messages::distribution_started
messages::distribution_finished
Agents can subscribe to these two messages and do whatever they need. For example, we add these two subscriptions to our telemetry_agent:
You might wonder why these are messages and not signals. Well, this is to allow SObjectizer developers to add some content to the message in the future.
It’s important to highlight that this follows a classical pattern in message passing-styled applications. We provided another example of this pattern in the previous post regarding the image_cache.
This covers nearly everything you need to begin working with telemetry! In the upcoming section, we’ll introduce another telemetry capability of SObjectizer that provides information about the time spent in dispatcher threads, essential to get a snapshot of the exhibited performance of one or more agents.
Observing thread activity
An additional category of telemetry data available, not provided as quantity, pertains to the time spent inside event-handlers and the time spent waiting for the next event in threads managed by dispatchers. This feature is not enabled by default to prevent any negative impact on dispatchers’ performance. Enabling this support must be done individually for a specific dispatcher or for the entire environment. For instance:
auto disp = so_5::disp::active_obj::make_dispatcher( env, "my_disp",
// Collecting of work thread activity is enabled
// in the dispatcher's parameters
disp_params_t{}.turn_work_thread_activity_tracking_on()
);
To enable support for all but certain dispatchers, we typically enable the feature globally while selectively disable it for some:
so_5::launch(
[]( so_5::environment_t & env ) {
// ...
// disable this one
auto my_disp = so_5::disp::one_thread::make_dispatcher(
env, "my_disp",
so_5::disp::one_thread::disp_params_t{}
.turn_work_thread_activity_tracking_off() );
// ...
[]( so_5::environment_params_t & params ) {
// enable all the others
params.turn_work_thread_activity_tracking_on();
// ...
}
);
The telemetry data related to thread activity are distributed using the message type:
stats::messages::work_thread_activity
In addition to prefix and suffix strings, this type contains three information:
m_thread_id that is valued with the thread identifier related to the data;
m_working_stats that contains information on the time spent in event handlers;
m_waiting_stats that contains information on the time spent waiting for new events.
m_working_stats and m_waiting_stats have type so_5::stats::activity_stats_t that contains:
m_count that is the number of events collected so far (this value won’t decrease);
m_total_time that is the total time spent for events so far (this value won’t decrease);
m_avg_time that is the average time spent for events so far.
In essence, the “working stats” object includes metrics regarding the time during which the specific thread was engaged in processing work, akin to the concept of “service time” we explored in a previous post. Conversely, the “waiting stats” object contains details about the duration spent awaiting new events (that is not the “waiting time” discussed before).
Let’s see this in action. Suppose we have this setup:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer_recursive>(main_channel, commands_channel);
c.make_agent<maint_gui::remote_control>(commands_channel, message_queue);
c.make_agent_with_binder<face_detector>(
make_dispatcher(sobjectizer.environment(), "face_detector",
so_5::disp::active_obj::disp_params_t{}.turn_work_thread_activity_tracking_on().binder()),
main_channel);
c.make_agent<telemetry_agent>();
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
This way, we name only face_detector‘s dispatcher face_detector. Also, to keep “ordinary” telemetry data about our face_detector dispatcher, we change telemetry_agent's filter this way:
As evident, there are no events (demands.count=0) and the total time spent on active work remains constant. Also, both the working and waiting counters do not increase, but only the waiting time increases. In practical terms, this suggests that the thread is effectively idle. This aligns with our scenario, where we expect no active work from the face_detector until frames are received.
Then we press ‘Enter’ to acquire frames and the log changes a bit:
Now, demands.count fluctuates between 0 and 1. This means, in practice, the thread is fast enough to dequeue and process events from the queue. Also, other metrics are increasing. This means, the thread is doing some work. It appears that the face_detector is consuming, on average, 18ms per event. It’s worth noting that this average is computed across the entire set of events from the start, not just the last batch. This detail is crucial because libraries often have warm-up times that can influence this calculation. Hence, for precise profiling, it’s advisable to conduct tests in a more controlled environment. Nonetheless, this provides a general insight into the situation: the face detector’s work is sustainable within the system, with the total waiting time surpassing the total working time!
Suppose at this point, we simply add another face_detector to the system, using the same dispatcher in order to include it to the telemetry log:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](coop_t& c) {
c.make_agent<image_producer_recursive>(main_channel, commands_channel);
c.make_agent<maint_gui::remote_control>(commands_channel, message_queue);
const auto disp = make_dispatcher(env.environment(), "face_detector", so_5::disp::active_obj::disp_params_t{}.turn_work_thread_activity_tracking_on());
c.make_agent_with_binder<face_detector>(disp, mbox);
c.make_agent_with_binder<face_detector>(disp, mbox);
c.make_agent<telemetry_agent>();
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
As before, before starting the camera acquisition, the log is quite predictable:
As you see, two face_detectors working concurrently within the system are suffering a bit: each requires double the time taken to process a single frame when operating individually! Also, look at the waiting event counters: at times, they remain constant, indicating that the thread is consistently saturated and it rarely gets a break. Moreover, pay attention to the trend of both demands.count: initially, it appears that thread 30292 can dequeue events more rapidly, but then it starts buffering. Conversely, thread 15092 follows an opposite trend.
Thus, enabling this additional telemetry collection on thread activity is convenient to spot possible issues related to event handlers. However, as the documentation remembers, the impact of this feature largely depends on the type of dispatcher and the load profile. For one_thread dispatchers handling heavy message streams, this impact is scarcely noticeable. However, for active_obj dispatchers dealing with occasional messages, performance can decrease by 3-4 times. Consequently, it’s challenging to provide precise numbers on cumulative performance loss due to the significant variability in results.
Nevertheless, it’s important to emphasize that this mechanism is considered secondary, primarily intended for debugging and profiling purposes. Therefore, it’s imperative to assess the performance impact of work thread activity tracking on your application. Only after thorough evaluation should a decision be made regarding whether to enable this mechanism in the production environment.
Design considerations
The first aspect we discuss in this brief section regards how to integrate telemetry support into our applications (existing or new).
First, for “ordinary” telemetry (not related to threading activity), we can easily integrate it by utilizing agents similar to telemetry_agent. Runtime monitoring can be toggled on and off dynamically without much additional effort, simply by accessing the environment instance. It’s common to integrate the application with commands, as demonstrated with telemetry_agent, and to have multiple agents that process specific telemetry information.
When telemetry is enabled, we can introduce specific agents based on the type of issue we’re investigating or the data we’re interested in. These agents might be always up and running, like telemetry_agent, or created on demand. The approach depends on the specific requirements and architecture of the application.
On the contrary, thread activity monitoring is more intrusive and necessitates modifications to how a dispatcher is instantiated. Ideally, we suggest incorporating this setting into the application’s configuration. However, in cases where the application needs to allow interactive toggling of activity tracking, the only option is to recreate the dispatchers. This typically involves deregistering some cooperations and agents, potentially causing temporary interruptions in their operation.
The second aspect regards how to add our own telemetry data into the telemetry system. It’s quite easy, as we only need to implement the interface stats::source_t that consists of a single function. For example:
The stats controller invokes this function of all the registered data sources when it’s time to “sample” telemetry data. It’s important to mention a couple of things regarding prefixes and suffixes:
prefix is limited to 47 characters + null-terminator (exceeding characters will be discarded by quantity‘s constructor);
suffix just copies the given pointer and not the data. This means, the given string should be either statically allocated or kept alive until the quantity is referenced. Typically, we use statically allocated strings or string literals in this case. It’s important to note that comparing two suffixes is the same as comparing their two pointers and not the content they point to.
To register a new data source, we add an instance of it to the stats_repository, a special object that collects all the data sources. It’s accessible from the environment:
It’s mandatory to keep the instance alive until the system is up and running. Typically, dispatchers implement the data source interface or keep a data source instance alive. Thus, whenever we develop a custom dispatcher intended for production, it’s good practice to add telemetry support this way. Additionally, it’s important to manually remove the data source to prevent potential issues where the stats controller attempts to call distribute() while the data source is being destructed.
To simplify this process, SObjectizer offers a couple of wrappers that handle the registration and deregistration of a data source automatically in a RAII fashion:
auto_registered_source_holder_t
manually_registered_source_holder_t
The key distinction between the two lies in the manual control over registration and deregistration provided by the latter, while still automating the removal during destruction if necessary. A minimal example is provided here below:
class some_agent final : public so_5::agent_t
{
so_5::stats::auto_registered_source_holder_t<my_data_source> m_ds_holder;
public:
some_agent(agent_context_t ctx )
: so_5::agent_t(std::move(ctx)), m_ds_holder(so_5::outliving_mutable( so_environment().stats_repository() ))
{}
};
int main()
{
so_5::launch( [](so_5::environment_t & env) {
env.introduce_coop([](so_5::coop_t& coop) {
// ... other agents
coop.make_agent<some_agent>();
} );
});
}
On the other hand, if we need to defer adding the data source to the stats controller, we might opt for manually_registered_source_holder_t:
class some_agent final : public so_5::agent_t
{
so_5::stats::manually_registered_source_holder_t<my_data_source> m_ds_holder;
public:
some_agent(agent_context_t ctx )
: so_5::agent_t(std::move(ctx))
{}
void so_evt_start() override
{
m_ds_holder.start(so_5::outliving_mutable( so_environment().stats_repository() ) );
}
};
Additionally, manually_registered_source_holder_t provides a stop() function to remove the data source before destruction.
Takeaway
In this episode we have learned:
SObjectizer provides a feature to collect and distribute runtime monitoring information that are telemetry data regarding its internals;
runtime monitoring is disabled by default as it might have a negative performance impact;
when enabled, telemetry data are collected and distributed by the stats controller, an entity that runs in a dedicated thread and is accessible from the environment using env.stats_controller();
to enable runtime monitoring, we call env.stats_controller().turn_on();
to disable runtime monitoring, we call env.stats_controller().turn_off();
the stats controller distributes data at intervals configured using set_distribution_period(number-of-secs);
distribution of telemetry data happens as usual: subscriptions to a certain message box;
the stats controller provides access to the standard message box for telemetry data through mbox();
telemetry data are represented by messages::quantities<size_t> which, in addition to the value, includes the data source name in the form of prefix and suffix;
the data source prefix identifies a group of related data sources (e.g. a particular dispatcher);
the data source suffix identifies the particular category of telemetry information (e.g. size of the event queue);
typically, we use delivery filters to keep only telemetry data we are interested in;
at every interval, all the telemetry quantities are delivered; to identify batches, two special messages are sent by the stats controller: distribution_started and distribution_finished;
it’s possible to enable – per dispatcher and also globally – additional telemetry data regarding thread activity such as the time spent processing events;
thread activity statistics are delivered as messages of type messages::work_thread_activity;
to add custom data sources, we implement the interface source_t which provides a single function.
With the recent addition of Ronnie, a new developer unfamiliar with SObjectizer, we’ve encountered a common dilemma: choosing the appropriate dispatchers to bind agents to. While Ronnie grasps the concept of decomposing business logic into agents that exchange messages, selecting the right dispatchers presents a challenge. To address this, we’ve scheduled pair programming sessions with Ronnie to share our guidelines and considerations on dispatcher binding.
Stay tuned for the next installment, where we delve into this topic in detail.
When an actor requires performing certain actions at shutdown, we typically consider using so_evt_finish(). However, if the operation involves message passing, so_evt_finish() is not the right choice as it might be too late for receivers to get the message. Indeed, agents within deregistering cooperations are unable to receive new messages. This means that a message dispatched from so_evt_finish() is not assured to be received by subscribers, as they could have already been deregistered or prevented from processing new messages (technically, they are unbound from the event queue).
Delivering messages during shutdown is a common problem in message passing applications, and frameworks often provide features to address it.
This issue crosses our path as we delve into the implementation of a new business need. During the recent planning session, Robin, our product owner, presented the team with a new opportunity: the company is embarking on a new project where calico could be an excellent solution. However, for being used in this project, there’s one missing feature: the ability to cache and process images in size-limited batches. Collaborating with Robin, we gathered additional details and determined that we require a new agent capable of storing images up to a specified limit and then transmitting them all to an output channel.
The requirement is somewhat ambiguous: should we transmit the entire batch or individual images? We’ll proceed with the assumption that we can send them one by one. This approach ensures compatibility with existing agents, allowing them to function seamlessly. For instance, if the image_tracer subscribes to the output of this “cache agent,” it will eventually receive and handle several images without requiring any changes to its implementation. In contrast, handling a “batch” would necessitate transmitting and subscribing to a new type of message.
The logic behind the “cache agent” is straightforward: it accumulates images up to a specified limit. Once this limit is reached, it sends all the accumulated images to an output channel, effectively flushing the cache to restart the process. Alternatively, accumulation can be triggered by a signal in other scenarios. (e.g. we might want to cache the entire “acquisition” that occurs between two commands) but we stick with the size limit approach that is enough for the purpose of this article.
As we explored in a previous post, we use message_holder_t to participate in the ownership of the image in order not to copy data.
At this point, we seek clarification from Robin on a crucial matter: what action should be taken at shutdown if the cache still holds some data? After consulting with the team from the new project, Robin returns with a conservative decision: they prefer that any remaining content be sent to the output channel. To elaborate, Robin specifies that the cache will output to a channel which will be subscribed from the network, exploiting our gRPC service_facade agent.
However, if we send leftovers from so_evt_finish() they are not guaranteed to be received. We need to explore another feature of SObjectizer designed to solve this problem.
Stop guards
The solution offered by SObjectizer is called shutdown prevention schema and it’s provided as the concept of stop guard.
The idea is pretty intuitive: we can install “stop guards” that are classes implementing the stop_guard_t interface consisting of a single stop function:
class my_stop_guard final : public so_5::stop_guard_t
{
public:
void stop() noexcept override
{
// ...some operation...
// I can so_5::send data here!
}
// ...
};
When the environment is requested to stop by calling environment_t::stop(), SObjectizer does not simply initiate the shutdown procedure but it first calls stop_guard_t::stop() function for every installed stop guard. This operation is synchronous and causes the thread calling environment_::stop() to block until each stop() returns. For instance, if we let an instance of wrapped_env_t within the main function to automatically trigger the shutdown, stop() will be invoked from the main thread (this is our scenario in calico).
Then SObjectizer waits until all the stop guards are removed. Hence, we must remove all installed stop guards at some point. Once they are all removed, the environment initiates the shutdown operation, as usual. It’s worth reiterating this point: SObjectizer does not impose a time limit for the shutdown operation. This means that if any stop guard remains installed, the shutdown process will not start at all.
In other words, when stop_guard_t::stop() is invoked, the shutdown process has not started yet. This means, agents are still bound to message queues and can receive messages. Thus, so_5::sending a message at that point is guaranteed to be delivered. Now, it should clear why this is called “shutdown prevention”.
The pattern works this way:
a stop guard is installed by using so_environment::setup_stop_guard(guard);
guard is an instance of shared_ptr<stop_guard_t> (or anything convertible);
a stop guard is removed by using so_environment::remove_stop_guard(guard).
Now, let’s explore how to address the shutdown requirement within the image_cache agent.
First of all, we craft a stop guard that sends a signal to image_cache to inform the shutdown is upcoming. The implementation might be included into image_cache as it’s an internal detail:
class image_cache final : public so_5::agent_t
{
struct shutdown_requested final : so_5::signal_t {};
class cache_stop_guard final : public so_5::stop_guard_t
{
public:
cache_stop_guard(so_5::mbox_t channel)
: m_channel(std::move(channel))
{
}
void stop() noexcept override
{
so_5::send<shutdown_requested>(m_channel);
}
private:
so_5::mbox_t m_channel;
};
// ... as before
};
Then we must install the stop guard. This might be done in different places and we’ll get back to that later. For now, let’s do it in the agent’s constructor:
class image_cache final : public so_5::agent_t
{
// ... as before
public:
image_cache(so_5::agent_context_t ctx, so_5::mbox_t input, so_5::mbox_t output, unsigned size)
: agent_t(ctx), m_input(std::move(input)), m_output(std::move(output)), m_session_size(size),
m_accumulated(0), m_cache(size), m_shutdown_guard(std::make_shared<cache_stop_guard>(so_direct_mbox()))
{
so_environment().setup_stop_guard(m_shutdown_guard);
}
private:
// ... as before
so_5::stop_guard_shptr_t m_shutdown_guard;
};
stop_guard_shptr_t is just an alias for shared_ptr<stop_guard_t>.
Finally, we need to handle the signal shutdown_requested by flushing the cache and then removing the stop guard from the environment:
void so_define_agent() override
{
// ... as before
so_subscribe_self().event([this](so_5::mhood_t<shutdown_requested>) {
flush();
so_environment().remove_stop_guard(m_shutdown_guard);
});
}
Let’s see this in action:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const so_5::wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(so_5::disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](so_5::coop_t& c) {
c.make_agent<image_producer_recursive>(main_channel, commands_channel);
c.make_agent<maint_gui::remote_control>(commands_channel, message_queue);
const auto cache_out = sobjectizer.environment().create_mbox();
c.make_agent<image_cache>(main_channel, cache_out, 50);
c.make_agent<image_tracer>(cache_out);
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
The sequence of events will be as follows: after starting the acquisition, the image_tracer will receive data only when the image_cache sends a burst. Finally, upon request for shutdown, any remaining cache data will be delivered before the actual shutdown.
Consider that image_cache could potentially be extended to send two additional messages. These messages would be dispatched before the first image of each batch and after the last one. This approach enables receivers to identify the beginning and end of each batch. These are commonly referred to as batch_start and batch_end, or alternatively, burst_start and burst_end. It’s worth noting that starting messages could include details such as the number of images that will be included in the batch.
There are a few missing technical details about stop guards.
First of all, stop_guard_t::stop() is noexcept as it shouldn’t throw exceptions. This is because if an exception occurs, there is no way to rollback shutdown-specific actions that were performed prior to the exception. Consequently, if an exception is thrown, the shutdown preparation procedure could be disrupted without any opportunity for recovery.
Also, it is only possible to install stop guards before the first invocation of environment_t::stop(). Once stop() has been called, any subsequent attempts to call setup_stop_guard() will fail. By default, the setup_stop_guard() method will throw an exception if stop() has already been called. However, if this behavior is not suitable, it can be modified by providing a second argument to setup_stop_guard():
const auto result = so_environment().setup_stop_guard(
my_guard,
stop_guard_t::what_if_stop_in_progress_t::return_negative_result );
if(stop_guard_t::setup_result_t::ok != result)
{
// ... handle this condition properly
}
Finally, it’s important to clarify that calling remove_stop_guard multiple times with the same instance is permitted. SObjectizer simply ignores stop guards that are not currently installed.
Deadlock alert
You may have noticed that installing stop guards could conceal a potential “resource leak” (not a memory leak) that leads to a deadlock. This is because remove_stop_guard() might not be invoked if certain issues arise (or by mistake) and we have no automatic cleanup in place. For example, this can occur in the case of an exception, such as one thrown from so_define_agent() or any event handlers.
In such cases, setup_stop_guard() is not followed by a corresponding call to remove_stop_guard(), preventing the shutdown process to start and the program to terminate.
A solution to this problem consists in “guarding the guard” that is introducing a guard type that simply removes the stop guard when destroyed. Here is a minimal example (there exist other solutions):
Then we can incorporate this wrapper into the agent, for example:
class image_cache final : public so_5::agent_t
{
// ... as before
public:
image_cache(so_5::agent_context_t ctx, so_5::mbox_t input, so_5::mbox_t output, unsigned size)
: agent_t(ctx), m_input(std::move(input)), m_output(std::move(output)),
m_session_size(size), m_accumulated(0), m_cache(size),
m_guard_remover(so_environment(), std::make_shared<cache_stop_guard>(so_direct_mbox()))
{
}
// ... as before
void so_define_agent() override
{
// ... as before
so_subscribe_self().event([this](so_5::mhood_t<shutdown_requested>) {
flush();
m_guard_remover.remove();
});
}
private:
// ... as before
guard_remover m_guard_remover;
};
We opted for encapsulating the stop guard setup into the “stop guard remover”, but this is not the only option (also, we don’t need to reference the stop guard from image_cache anymore). By calling remove() explicitly, we can anticipate the stop guard removal. However, since we are allowed to call remove_stop_guard() multiple times with the same instance, we don’t need to check if the guard has been already removed.
This guard ensures the stop guard is removed even in case of issues leading the agent to be deregistered and destroyed before the normal shutdown.
It’s worth mentioning a brief discussion I had with Yauheni regarding this topic. Another approach to address this issue involves installing a stop guard in so_evt_start() and removing it in so_evt_finish(). In this scenario, when the agent is notified by the stop guard that shutdown is imminent, it must deregister itself (as we learned in a previous post). This action triggers so_evt_finish() prematurely, leading to the removal of the stop guard.
Just to let you know that SObjectizer’s companion project, so5extra, provides the shutdowner class that implements the shutdown prevention schema in a different way.
Takeaway
In this episode we have learned:
during shutdown, agents can’t receive new messages; this means, a message sent from so_evt_finish() is not guaranteed to be delivered;
to solve this problem, SObjectizer provides a shutdown prevention schema called stop guard;
we can install stop guards whose stop() function will be called just before the shutdown starts;
a stop guard is installed using setup_stop_guard();
stop() functions are called from the same thread requesting the shutdown;
SObjectizer then expects that all installed stop guards are removed, then it starts the shutdown procedure as usual;
a stop guard is removed using remove_stop_guard();
calling remove_stop_guard() multiple times with the same instance is permitted. SObjectizer simply ignores stop guards that are not currently installed;
stop_guard::stop() is noexcept and shouldn’t throw exceptions;
a stop guard is like an acquired resource: not removing it leads to preventing shutdown;
to ensure that a guard is removed even in case of exceptions, RAII wrappers might be employed.
As the new feature has been implemented during this sprint, we are collaborating with the new project’s team to configure and test calico for their specific requirements. In the meantime, we receive a message from Helen who has something particularly intriguing to share, following up our recent discussion about performance.
In the next post, we’ll delve into the standard telemetry metrics offered by SObjectizer right out of the box.
Last time we promised Helen to show a feature of SObjectizer that can prevent the copying of execution_demand_t instances when they are transmitted from push functions of service_time_estimator_dispatcher and later received from the worker thread.
This is the implementation of the dispatcher:
class service_time_estimator_dispatcher : public so_5::event_queue_t, public so_5::disp_binder_t
{
public:
service_time_estimator_dispatcher(so_5::environment_t& env, so_5::mbox_t output, unsigned messages_count)
: m_event_queue(create_mchain(env)), m_start_finish_queue(create_mchain(env)), m_output(std::move(output)), m_messages_count(messages_count), m_messages_left(messages_count)
{
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
receive(from(m_event_queue_start_stop).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
// ... as before
});
receive(from(m_event_queue).handle_all(), [thread_id, this](so_5::execution_demand_t d) {
// ... as before
});
receive(from(m_event_queue_start_stop).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
// ... as before
});
} };
}
void push(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_event_queue, std::move(demand));
}
void push_evt_start(so_5::execution_demand_t demand) override
{
so_5::send<so_5::execution_demand_t>(m_start_finish_queue, std::move(demand));
}
void push_evt_finish(so_5::execution_demand_t demand) noexcept override
{
so_5::send<so_5::execution_demand_t>(m_event_queue_start_stop, std::move(demand));
close_retain_content(so_5::terminate_if_throws, m_event_queue);
}
// ... as before
private:
// ... as before
};
As we have learnt, in SObjectizer messages are exchanged as immutable, since this is a straightforward and secure approach for implementing interaction within a concurrent application:
any number of receivers can simultaneously receive a message instance;
messages can be redirected to any number of new receivers;
messages can be stored for later processing.
However, using immutable messages implies that modifying a message requires copying it and altering the local instance. Consequently, there are scenarios where this approach might be impractical, such as when the message contains non-copyable data, and inefficient, particularly when dealing with large message sizes.
A few workarounds are available, such as encapsulating data within shared_ptr or such wrappers – a strategy akin to the one inherited from OpenCV for avoiding image data copying – or utilizing the mutable type specifier (brrr…). However, both approaches either introduce safety concerns or incur unnecessary overhead.
The real solution consists in using another slick feature of SObjectizer: mutable messages.
Mutable messages
SObjectizer supports explicitly-typed mutable messages for 1:1 exchanges. Specifically, a mutable message can only be sent to Multiple-Producer Single-Consumer (MPSC) message boxes (aka: the direct message box of an agent) or chains. This restriction implies that there can be a maximum of one receiver for the message. Any attempt to send a mutable message to a Multiple-Producer Multiple-Consumer (MPMC) message box will result in a runtime exception. In other words, mutable messages can’t be used with named and anonymous message boxes created using environment_t::create_mbox().
A mutable message is sent by expressing mutability through the wrapper so_5::mutable_msg<Msg>:
send<mutable_msg<int>>(dst, 10);
and it’s received using either so_5::mutable_mhood_t<Msg> or mhood_t<mutable_msg<M>>. The former serves as a shorthand for the latter, which can be convenient in generic code, such as:
template<typename M> // Can be Msg or mutable_msg<Msg>
class example : public so_5::agent_t {
...
void on_message(mhood_t<M> cmd) {
...
}
};
Since, mutability introduces a new type, a mutable message of type M is a distinct type from an immutable message of type M. As a result, agents may have two different handlers for the same message type, each referring to the same messages but with a different mutability property.
As mentioned earlier, a mutable message can only have a single receiver. In essence, mhood_t<mutable_msg<M>> behaves similarly to unique_ptr: it cannot be copied, only moved. Moving a mutable message is equivalent to redirecting it to another destination. Consequently, a mutable message that has been moved from becomes empty, with its pointee being set to nullptr.
Therefore, mutable messages offer a safer alternative compared to any workaround involving immutable messages, as only one receiver can access a mutable message instance at any given time.
At this point, we leverage this understanding to modify the service_time_estimator_dispatcher to accommodate the usage of mutable messages:
class service_time_estimator_dispatcher : public so_5::event_queue_t, public so_5::disp_binder_t
{
public:
service_time_estimator_dispatcher(so_5::environment_t& env, so_5::mbox_t output, unsigned messages_count)
: m_event_queue(create_mchain(env)), m_start_finish_queue(create_mchain(env)), m_output(std::move(output)), m_messages_count(messages_count), m_messages_left(messages_count)
{
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
receive(from(m_event_queue_start_stop).handle_n(1), [thread_id, this](mutable_mhood_t<so_5::execution_demand_t> d) {
d->call_handler(thread_id);
});
receive(from(m_event_queue).handle_all(), [thread_id, this](mutable_mhood_t<so_5::execution_demand_t> d) {
const auto tic = std::chrono::steady_clock::now();
d->call_handler(thread_id);
const auto toc = std::chrono::steady_clock::now();
const auto elapsed = std::chrono::duration<double>(toc - tic).count();
});
receive(from(m_event_queue_start_stop).handle_n(1), [thread_id, this](mutable_mhood_t<so_5::execution_demand_t> d) {
// ... as before
});
} };
}
void push(so_5::execution_demand_t demand) override
{
so_5::send<so_5::mutable_msg<so_5::execution_demand_t>>(m_event_queue, std::move(demand));
}
void push_evt_start(so_5::execution_demand_t demand) override
{
so_5::send<so_5::mutable_msg<so_5::execution_demand_t>>(m_start_finish_queue, std::move(demand));
}
void push_evt_finish(so_5::execution_demand_t demand) noexcept override
{
so_5::send<so_5::mutable_msg<so_5::execution_demand_t>>(m_event_queue_start_stop, std::move(demand));
close_retain_content(so_5::terminate_if_throws, m_event_queue);
}
// ... as before
};
As observed, the modifications are minimal and primarily affect the utilization of the message in using the arrow operator. This adjustment would have been seamlessly incorporated if we had employed mhood_t from the beginning.
A classic pattern
An interesting use case of mutable messages arises when a message requires processing through a pipeline either statically or dynamically-defined. In essence, we define a sequence of processing steps (handled by different agents) where each step receives the message, executes its functionality, and then sends the (modified) message to the subsequent step. This sequential execution enables a message to be processed by multiple services in order, without requiring a coordinating component.
When thinking about calico, we already offer this flexibility as agents can be combined as required through channels, whether named or not. However, this operates with immutable messages, and modifying the message at each step necessitates data copying and dynamic memory allocation for sending it, as seen, for example, in image_resizer and face_detector.
Considering that this approach may be suitable for numerous use cases, we might encounter “hot paths” in our applications where copying data is undesirable, and minimizing dynamic allocations is crucial. Here is where mutable messages come into play.
However, even when utilizing mutable messages, there’s another intriguing aspect to consider: the efficient pipeline’s outcome may need to be delivered to other agents that only necessitate read access, without any further modifications. Essentially, the mutable result should be turned into an immutable message and routed through other components. Is it possible to achieve this without requiring additional copies and dynamic allocations?
Yes, mutable messages can be turned into immutable messages efficiently (without allocating memory nor copying) through the free function to_immutable():
void last_pipeline_step(mutable_mhood_t<some_message> cmd)
{
// ...
// Now the mutable message will be resend as an immutable one.
so_5::send(some_channel, so_5::to_immutable(std::move(cmd)));
// cmd is a nullptr now and can't be used anymore.
}
It’s worth noting that, from SObjectizer’s standpoint, converting a mutable message into an immutable one essentially entails removing a sort of “mutability flag”. Consequently, the memory block of the message itself remains unchanged, ensuring efficient handling.
After removing mutability, the old message wrapper contains nullptr. In case you are wondering, an immutable message can’t be converted into a mutable one without copying the message itself into a newly-allocated one. Indeed, from a design point of view, it would be impossible to transform a shared reference into a singular reference (just like it’s not possible to convert a shared_ptr into a unique_ptr).
In the following example, we show a statically-defined pipeline that leverages mutable messages to avoid intermediate copies. This might be seen as an application of the Pipes and Filters pattern since the pipeline is statically defined. This means that each agent has a fixed “next” step (assembled during the initialization) that can’t be changed at runtime:
class step_1 : public so_5::agent_t
{
public:
step_1(so_5::agent_context_t ctx, so_5::mbox_t step_2_dst)
: agent_t(ctx), m_step_2_dst(std::move(step_2_dst))
{
}
void so_define_agent() override
{
so_subscribe(so_environment().create_mbox("main")).event([this](const cv::Mat& img) {
auto local_image = img.clone();
resize(local_image, local_image, {}, 0.5, 0.5);
so_5::send<so_5::mutable_msg<cv::Mat>>(m_step_2_dst, std::move(local_image));
});
}
private:
so_5::mbox_t m_step_2_dst;
};
class step_2 : public so_5::agent_t
{
public:
step_2(so_5::agent_context_t ctx, so_5::mbox_t step_3_dst)
: agent_t(ctx), m_step_3_dst(std::move(step_3_dst))
{
}
void so_define_agent() override
{
so_subscribe_self().event([this](so_5::mutable_mhood_t<cv::Mat> img) {
line(*img, { img->cols/2, 0 }, { img->cols/2, img->rows }, { 0, 0, 0 }, 3);
line(*img, { 0, img->rows/2 }, { img->cols, img->rows/2 }, { 0, 0, 0 }, 3);
so_5::send(m_step_3_dst, std::move(img));
});
}
private:
so_5::mbox_t m_step_3_dst;
};
class step_3 : public so_5::agent_t
{
public:
step_3(so_5::agent_context_t ctx)
: agent_t(ctx)
{
}
void so_define_agent() override
{
so_subscribe_self().event([this](so_5::mutable_mhood_t<cv::Mat> img) {
cvtColor(*img, *img, cv::COLOR_BGR2GRAY);
so_5::send(so_environment().create_mbox("output"), to_immutable(std::move(img)));
});
}
};
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const so_5::wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
// here is the setup of the pipeline
sobjectizer.environment().introduce_coop(so_5::disp::active_group::make_dispatcher(sobjectizer.environment()).binder("pipeline"), [&](so_5::coop_t& c) {
auto step_3_dst = c.make_agent<step_3>()->so_direct_mbox(); // this sends data to "output" channel
auto step_2_dst = c.make_agent<step_2>(step_3_dst)->so_direct_mbox();
c.make_agent<step_1>(step_2_dst); // this gets data from "main" channel
});
sobjectizer.environment().introduce_coop(so_5::disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](so_5::coop_t& c) {
c.make_agent<producers::image_producer_recursive>(main_channel, commands_channel); // this sends data to "main" channel
c.make_agent<agents::maint_gui::remote_control>(commands_channel, message_queue);
c.make_agent<agents::maint_gui::image_viewer>(sobjectizer.environment().create_mbox("output"), message_queue);
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
We grouped the pipeline’s agents into a dedicated cooperation using an active_group dispatcher (aka: they all share the same worker thread for processing).
The situation becomes a bit more complex when the pipeline needs to be dynamically assembled, such as in the routing slip pattern. In essence, the processing steps are not predetermined but can change dynamically. In this scenario, a potential implementation involves integrating the “routing” as part of the message itself. This means, each processing step performs its work and then passes the modified message to the “next” step that is obtained from the message. In this scenario, utilizing mutable messages serves two purposes: not only does it prevent the need to copy the processed instance every time (as before), but it also facilitates “stepping” the same routing object along the pipeline (to obtain the next destination).
However, combining the payload instance (e.g. the image) with the routing object doesn’t eliminate the need for a final dynamic allocation when the payload needs to be converted into an immutable message and passed through the rest of the application. While this might not be a significant concern, it’s worth noting. The reason is simple:
Even though copying the data can be avoided by moving, we can’t eliminate the dynamic allocation that occurs when using the send function in this context.
Anyway, let’s see a possible implementation of this pattern. First of all, we define the message type, as discussed before:
route_slip_message is the type that will circulate through the pipeline, consisting of the payload (e.g. the image) and the routing object;
route_slip is that “routing object” implemented as a vector of channels equipped with a simple next function that is used to obtain the next channel of the pipeline. In other words, this defines the sequence of steps;
send_to_next_step is a function that simply sends the message to the next channel.
Certainly, there could be other implementations, but the objective here is to keep things simple enough to grasp the concept.
Then, we introduce some “processing steps”. Every step is an agent that handles a mutable route_slip_message by processing it and then sending it to the next step:
Also, we add the “last step” that is slightly different: it will just extract and send the cv::Mat to a separate destination channel. While it could be part of the same route_slip instance, for clarity, we prefer having a separate field:
As said before, the dynamic allocation here can’t be avoided.
Lastly, we need the “router” which dynamically assembles the pipeline. To maintain simplicity, we also assign it the responsibility of creating the cooperation of agents. We’ll store their direct message boxes in a map, allowing us to retrieve them by name, simulating a configuration from a file or similar source:
class slip_router : public so_5::agent_t
{
public:
slip_router(so_5::agent_context_t ctx, so_5::mbox_t source, so_5::mbox_t last)
: agent_t(ctx), m_source(std::move(source)), m_last(std::move(last))
{
}
void so_evt_start() override
{
so_environment().introduce_coop(so_5::disp::active_group::make_dispatcher(so_environment()).binder("slip"), [this](so_5::coop_t& c) {
m_available_steps["resize"] = c.make_agent<resize_step>()->so_direct_mbox();
m_available_steps["add_crosshairs"] = c.make_agent<add_crosshairs_step>()->so_direct_mbox();
m_available_steps["to_grayscale"] = c.make_agent<to_grayscale_step>()->so_direct_mbox();
m_available_steps["last"] = c.make_agent<slip_last_step<cv::Mat>>(m_last)->so_direct_mbox();
});
}
void so_define_agent() override
{
so_subscribe(m_source).event([this](const cv::Mat& img) {
auto local_image = img.clone();
// imagine this is created dynamically and only when something changes...
route_slip_message slip{ {{
m_available_steps.at("add_crosshairs"),
m_available_steps.at("to_grayscale"),
m_available_steps.at("last")}}, // we mustn't forget this one!
std::move(local_image) };
const auto first_step_channel = slip.next();
so_5::send<so_5::mutable_msg<route_slip_message<cv::Mat>>>(first_step_channel, std::move(slip));
});
}
private:
so_5::mbox_t m_source;
so_5::mbox_t m_last;
std::map<std::string, so_5::mbox_t> m_available_steps;
};
In this example, the pipeline is generated for each image. However, we could potentially trigger the creation of a new pipeline based on a specific “configuration” change or a command. Things can become more sophisticated as needed, but this is the general pattern: the routing is embedded within the message, eliminating the necessity for central coordination.
Here is an example of usage:
int main()
{
const auto ctrl_c = utils::get_ctrlc_token();
const so_5::wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(so_5::disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](so_5::coop_t& c) {
c.make_agent<image_producer_recursive>(main_channel, commands_channel); // this sends data to "main" channel
c.make_agent<remote_control>(commands_channel, message_queue);
c.make_agent<image_viewer>(sobjectizer.environment().create_mbox("output"), message_queue);
c.make_agent<slip_router>(main_channel, sobjectizer.environment().create_mbox("output"));
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
As you see, the user does not see the pipeline agents that are, instead, created by the slip_router.
Consider that our agents might be easily generalized into a customizable unified agent, for example:
As mentioned above, such patterns are useful not only in scenarios where flexibility is required, but also in others where copying data is not desirable.
Mutable messages and timed send functions
The last thing to know about mutable messages regards timed send functions: since mutable messages cannot be copied but only moved, they cannot be sent periodically using the send_periodic function if the period is nonzero; otherwise, an exception will be thrown. However, they can be sent using the send_delayed function:
// ok:
auto timer = so_5::send_periodic<so_5::mutable_msg<some_message>>(
dest_mbox,
200ms, // Delay before message appearance.
0ms, // Period is zero.
...);
// ko: an exception will be thrown
auto timer = so_5::send_periodic<so_5::mutable_msg<some_message>>(
dest_mbox,
200ms, // Delay before message appearance.
150ms, // Period is not zero.
...);
// ok:
so_5::send_delayed<so_5::mutable_msg<some_message>>(
dest_mbox,
200ms, // Delay before message appearance.
... // some_message's constructor args.
);
Additionally, it’s just worth mentioning that signals can’t be mutable. It wouldn’t make any sense.
Takeaway
In this episode we have learned:
SObjectizer supports explicitly-typed mutable messages for 1:1 exchanges, meaning that an agent receiving a mutable message can safely modify it;
mutable messages are sent by declaring the type as mutable_msg<Msg>;
mutable messages are received using either mutable_mhood_t<Msg> or mhood_t<mutable_msg<M>>;
mutable messages can’t be copied, only moved;
mutable messages have only one receiver, this means that mutable messages can’t be used with named and anonymous message boxes created using environment_t::create_mbox() functions, because they are MPMC (doing that would result in an exception);
to_immutable(msg) is used to turn a mutable message into an immutable instance, avoiding creating a new message instance or copying data;
We have just met some colleagues gossiping about the sprint planning next week. It seems our product manager will unveil some exciting news about a potential opportunity in a next-generation project at the company.
However, they anticipated we’ll work on an issue related to delivering messages at shutdown…
The deep dive into performance is reaching its conclusion, and in this final part, we will delve into a few typical benchmarks of actor model frameworks, applying these concepts to SObjectizer. Also, after reading this article, we will have some more understanding of the hidden costs of the framework and some tuning options which are available.
First of all, regardless of internal details and design decisions, in-process actor model frameworks commonly share some fundamental features:
creation, destruction, and management of agents;
message delivery;
thread management.
Thus, benchmarks typically assess:
performance of creating and destroying agents;
performance of message passing in both 1:1 and 1:N scenarios;
above benchmarks applied in both single- and multi-threaded cases.
SObjectizer provides some benchmarks in this official folder. Also, there is an old but still interesting discussion about comparing performance of SObjectizer and CAF that explores some benchmarks here.
Skynet: performance of managing agents
The initial benchmark reveals the overhead of creating and destroying agents, which may seem marginal but is significant in some scenarios. This test provides insights into the implicit cost of agent management in SObjectizer. It’s crucial to note that agents in SObjectizer possess features tailored for structuring work in concurrent applications. Agents can have states, define subscriptions, and are organized in cooperations. Therefore, they come with a certain cost for a reason. Dynamically spawning thousands of agents might pose a challenge, and this benchmark is designed to illustrate this aspect.
We propose the Skynet benchmark that consists in creating an agent which spawns 10 new agents, each of them spawns 10 more agents, and so on, until one million agents are created on the final level. Then, each of them returns back its ordinal number (from 0 to 999999), which are summed on the previous level and sent back upstream, until reaching the root (the answer should be 499999500000):
Disclaimer: don’t use this benchmark to compare different concurrent entities like “futures vs actors”, as the complaints here and here rightly highlight. It does not make any sense.
As you can imagine, every computation of agents in this test is a “no-op”, since the primary focus is on measuring the cost of spawning agents and exchanging (a few) control messages. The benchmark measures the wall time of the whole experiment (the elapsed total time).
A possible implementation is here below:
class skynet final : public so_5::agent_t
{
public:
skynet(so_5::agent_context_t ctx, so_5::mbox_t parent, size_t num, size_t size)
: agent_t(ctx), m_parent(std::move(parent)), m_num(num), m_size(size)
{}
void so_evt_start() override
{
if (1u == m_size)
{
so_5::send<size_t>(m_parent, m_num);
}
else
{
so_subscribe_self().event([this](size_t v) {
m_sum += v;
if (++m_received == divider)
{
so_5::send<size_t>(m_parent, m_sum);
}
});
so_environment().introduce_coop([&](so_5::coop_t& coop) {
const auto sub_size = m_size / divider;
for (unsigned int i = 0; i != divider; ++i)
{
coop.make_agent<skynet>(so_direct_mbox(), m_num + i * sub_size, sub_size);
}
});
}
}
private:
static inline size_t divider = 10;
const so_5::mbox_t m_parent;
const size_t m_num;
const size_t m_size;
size_t m_sum = 0;
unsigned int m_received = 0;
};
TEST(benchmarks, skynet)
{
const so_5::wrapped_env_t sobjectizer;
const auto output = create_mchain(sobjectizer.environment());
const auto tic = std::chrono::steady_clock::now();
sobjectizer.environment().introduce_coop([&](so_5::coop_t& c) {
c.make_agent<skynet>(output->as_mbox(), 0u, 1000000u);
});
size_t result = 0;
receive(from(output).handle_n(1), [&](size_t i) {
result = i;
});
std::cout << std::chrono::duration<double>(std::chrono::steady_clock::now() - tic) << "\n";
EXPECT_THAT(result, testing::Eq(499999500000));
}
On my machine (Intel i7-11850H @2.50GHz, 8 Cores), this test outputs consistently between 1.45s and 1.6s. However, it does not include agents deregistration time. The time approximately doubles if we include that cost:
Some numbers taken by changing both the size of the pool and the type of fifo strategy:
pool size
cooperative
individual
1
5.0s
5.0s
2
4.1s
5.1s
3
3.7s
5.6s
4
3.8s
7.1s
8
4.2s
14.5s
comparing different pool size and fifo strategies of skynet
Clearly, the elapsed time here includes also the cost of managing the thread pool, for this reason is higher than the single-threaded version.
In a private conversation, Yauheni briefly commented on the cost of agent and cooperation management: “the cost of registration/deregistration of cooperations in SObjectizer was always considerably big in comparison with alternatives. There were reasons for that: cooperations are separate objects, so in SObjectizer you have to create an agent (paying some price) and you have to create a cooperation (paying some price). Registration requires binding of an agent to a dispatcher (paying some price) and there is a cost you pay for the transaction – binding has to be dropped if something is going wrong (like an exception from so_define_agent()). Deregistration is a complex and asynchronous procedure that requires sending evt_finish event and placing the coop to the queue of coops for the final deregistration. It’s necessary to correctly join worker threads if they are allocated for agents from the cooperation, so paying some price again”.
Yauheni also highlighted that having too many agents is an observability nightmare, not just for debugging but also for monitoring performance indicators. Restricting the number of agents to a few hundred thousand shows a notable improvement. In fact, the single-threaded skynet with 100,000 agents takes between 25 to 29 milliseconds (including the destruction of agents).
Finally, consider scenarios where a significant number of agents are spawned at the startup of the application, as in the case of calico. In such scenarios, agents are created dynamically (e.g., from a configuration file) when the application starts, staying up and running for the rest of the time to handle messages.
Ping pong: performance of 1:1 messaging
When it comes to benchmarking one to one message passing performance, the “ping pong” benchmark is a classic. In this benchmark, two agents engage in an exchange of messages for a predefined number of iterations. The “pinger” agent sends a “ping” message and awaits a corresponding “pong” before sending another “ping.” Similarly, the “ponger” agent responds with a “pong” only after receiving a “ping.” This back-and-forth messaging continues for the specified number of times:
The “pinger” agent estimates the throughput by calculating the rate at which messages are exchanged, obtained by dividing the elapsed time by the number of iterations (likewise we did in our frequency_calculator from the first article of the performance series).
The benchmark becomes particularly insightful in two scenarios:
single-threaded execution: when both agents operate on a shared thread. This configuration highlights the efficiency of the message queue with only one worker thread, unaffected by external influences;
multi-threaded execution: when both agents run on separate threads. In this case, the benchmark serves as a means to measure the latency of message transmission between two working threads. The observed latency can vary depending on the synchronization mechanisms used by the worker threads and expectations regarding empty queues (aka: the dispatcher).
As threading is up to the dispatcher, the code for both will be almost the same. Here is the code of the first scenario:
we utilized so_5::launch, a self-contained function that executes a SObjectizer environment and keeps it active until explicitly halted (done when pinger::send_ping() is completed);
it was needed to set the output channel of both agents in order to use their direct message box (that is Multiple-Producer Single-Consumer channel);
the test reports both “throughput” and “real-throughput,” with the latter being twice the former. This is because the message exchange effectively involves twice the count (since each ping is accompanied by a pong), making the “real” throughput double. Typically, the “real” throughput is considered the reference number.
On my machine, this benchmark outputs something like this:
In other words, on my machine, the maximum “ping-pong throughput” is approximately 17 million messages per second. Typically, when you hear something like “this framework’s maximum throughput is X million messages per second”, it comes from a benchmark like this.
At this point, we might change the dispatcher to active_obj in order to give each agent its own worker thread. Here is the only piece of code to change:
Thus, the maximum throughput is approximately 2 million messages per second.
If we switch to a thread pool with 2 threads and cooperation FIFO (aka: a shared message queue), the performance fits approximately in the middle (10 million per seconds):
As we can expect, this is slightly worse than active_obj, presumably because the thread pool management costs a bit more.
The ping pong benchmark can be extended by introducing some work in agents, simulating CPU load, or by adding some sleep to simulate waiting for external resources to be available. Feel free to explore and test other dispatchers and configurations based on your preferences.
Also, it’s worth sharing another version based on “named channels” instead of direct message boxes. In other words, we’ll replace agent’s Multi-Producer Single-Consumer direct channels with arbitrary Multi-Producer Multi-Consumer message boxes:
As expected, there is a performance difference between MPSC (aka: direct message boxes) and MPMC message boxes, however in certain scenarios, it might be negligible. For example, in calico we have two main bottlenecks: the producer constrained by the camera’s frame rate, and possibly some resource-intensive agents (e.g. face_detector) operating in the order of milliseconds. Consequently, in our context, the difference between MPMC and MPSC channels is not significant.
In terms of message sending and processing in SObjectizer, it’s worth mentioning a few considerations that have an impact:
agents are finite-state machines, necessitating consideration of the agent’s current state during the message handler search;
agents can subscribe to messages from various mailboxes. Consequently, the process of selecting a handler must account for both the agent’s current state and the associated message mailbox;
the multi-consumer mailbox feature has some implications for the message dispatching process as the message box has to find all the subscribers for a certain message.
Performance of 1:N messaging
To assess the scenario of 1:N messaging, we design a benchmark closely aligned with our domain. In essence, a potentially fast producer sends data – say 100’000 numbers – to a specific named channel, and multiple agents – say 100 – are subscribed to that channel:
Initially, we use only two threads: one dedicated to the producer and a shared one dedicated to the others. Additionally, in the initial version, there is no work inside agents. Then, in a subsequent version, we introduce some little sleeping before replying to simulate concurrent operations without active CPU utilization (e.g. network usage). Finally, we add some CPU usage.
We create only one cooperation. The producer is bound to the default one_thread dispatcher, whereas the others are bound to an active_group to share the same thread. Also, for simplicity, all agents send back a message to the producer when they have handled all the messages. We measure the wall time of the whole experiment, including agent creation and deregistration, since the number of agents is small (remember the skynet benchmark shows the cost of managing 100’000 agents is less than a tenth of a second):
template<unsigned workers_count>
class producer final : public so_5::agent_t
{
public:
producer(so_5::agent_context_t c, unsigned message_count)
: agent_t(std::move(c)), m_message_count(message_count)
{
}
void so_evt_start() override
{
const auto tic = std::chrono::steady_clock::now();
const auto destination = so_environment().create_mbox("input");
for (unsigned i = 0; i < m_message_count; ++i)
{
so_5::send<unsigned>(destination, i);
}
const auto elapsed = std::chrono::duration<double>(std::chrono::steady_clock::now() - tic).count();
std::cout << std::format("1:N benchmark (message_count={} worker_count={}) => sending data: elapsed={}\n", m_message_count, workers_count, elapsed);
}
void so_define_agent() override
{
so_subscribe_self().event([this](unsigned worker_id) {
m_done_received[worker_id] = true;
if (m_done_received.all())
{
so_environment().stop();
}
});
}
private:
unsigned m_message_count;
std::bitset<workers_count> m_done_received;
};
class worker final : public so_5::agent_t
{
public:
worker(so_5::agent_context_t c, unsigned message_count, unsigned worker_id, so_5::mbox_t dest)
: agent_t(std::move(c)), m_message_count(message_count), m_worker_id(worker_id), m_input(so_environment().create_mbox("input")), m_output(std::move(dest))
{
}
void so_define_agent() override
{
so_subscribe(m_input).event([this](unsigned msg) {
if (--m_message_count == 0)
{
so_5::send<unsigned>(m_output, m_worker_id);
}
});
}
private:
unsigned m_message_count;
unsigned m_worker_id;
so_5::mbox_t m_input;
so_5::mbox_t m_output;
};
TEST(benchmarks, messaging_one_to_many)
{
constexpr auto workers_count = 100;
constexpr auto message_count = 100000;
const auto tic = std::chrono::steady_clock::now();
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop([&](so_5::coop_t& coop) {
const auto master_mbox = coop.make_agent<producer<workers_count>>(message_count)->so_direct_mbox();
const auto workers_dispatcher = so_5::disp::active_group::make_dispatcher(env).binder("workers");
for (auto i = 0u; i < workers_count; ++i)
{
coop.make_agent_with_binder<worker>(workers_dispatcher, message_count, i, master_mbox);
}
});
});
const auto elapsed = std::chrono::duration<double>(std::chrono::steady_clock::now() - tic).count();
std::cout << std::format("1:N benchmark (message_count={} worker_count={}) => overall: elapsed={}\n", message_count, workers_count, elapsed);
}
As you notice, we are also measuring the time taken for the sole sending operation. It will be useful.
On my machine, the benchmark prints something like this:
massive-send send time elapsed=0.6293867 [message_count=100000 worker_count=100]
massive-send elapsed=0.6358283 [message_count=100000 worker_count=100]
At this point, we might wonder how the outcome changes when more threads are involved. We start by replacing the dispatcher with an active_obj that binds each agent to a dedicated thread and event queue. The results:
massive-send send time elapsed=1.8008089 [message_count=100000 worker_count=100]
massive-send elapsed=1.8236707 [message_count=100000 worker_count=100]
Then we use thread pools and see the result. Using 4 threads and cooperation FIFO shows this situation:
massive-send send time elapsed=2.79563 [message_count=100000 worker_count=100]
massive-send elapsed=2.7978501 [message_count=100000 worker_count=100]
Individual FIFO makes performance worse:
massive-send send time elapsed=14.9737671 [message_count=100000 worker_count=100]
massive-send elapsed=14.9762084 [message_count=100000 worker_count=100]
What’s happening?
First of all, we observe sending time is almost equal to the total time in all the benchmarks. This is merely because the agents do nothing (their operations are just no-ops). In other words, we might argue that it takes more to send a single message than to handle it. Indeed, to send a message, SObjectizer will dynamically allocate memory and create a “demand” instance for each subscriber. Using multiple threads will also cause more thread preemption and context switches.
The story does not end here. The performance of individual FIFO is too poor to ignore, prompting us to delve deeper into the issue. At this point, we are ready to meet another advanced option of the thread_pool dispatcher: max_demands_at_once.
This option (officially explained here), determines how often a working thread will switch from one event queue to another. In other words, when a worker thread processes one event from a queue, the parameter max_demands_at_once determines how many events from a queue the thread has to process before switching to another queue. If the queue contains, let’s say, 5 events and max_demands_at_once is 3, the agent first handles 3 events and then moves on to another queue. Evidently, if the queue becomes empty before processing max_demands_at_once events, the thread switches to another non-empty queue.
The interesting fact is that turning max_demands_at_once to 1 on the 4-size individual thread pool dramatically improves the situation:
massive-send send time elapsed=1.4899536 [message_count=100000 worker_count=100]
massive-send elapsed=2.2166388 [message_count=100000 worker_count=100]
As said before, in both the versions the event queues will become empty quickly because processing events is faster than sending them. So, regardless of the value of max_demands_at_once, every worker should frequently switch from a queue to another non-empty queue as the current one will get empty just after processing one event. Thus, it seems that attempting to find a non-empty queue is more resource-intensive than switching to another non-empty queue when one is already being processed.
Without delving too deeply into internal details, Yauheni conducted additional tests and identified some reasons for this scenario. From a high level point of view, imagine there is contention on a lock that protects access to a list of non-empty agents’ queues. A queue is added to this list when it becomes non-empty. Similarly, it’s removed when it becomes empty. The problem is the “frequency” the queues become empty and non-empty, since the lock contention depends on this state change. With max_demands_at_once=4, since messages are handled quickly, the queues will become empty more frequently as every worker will “drain” the queue more quickly and the empty queue has to be removed from the list. And it will be added back to the list on the next “send” iteration. This removal/addition requires frequent lock acquisition. On the other hand, when max_demands_at_once=1, there will be more chances to have some messages left in the agent queues and there is no need to remove a queue from the list (and then add it again), so the list’s lock contention is much lower in that case.
To change this setting, we call the appropriate function on the bind_params_t object:
const auto workers_dispatcher =
so_5::disp::thread_pool::bind_params_t{}
.fifo(so_5::disp::thread_pool::fifo_t::individual)
.max_demands_at_once(1);
Now, we increase the number of workers while decreasing the number of messages:
As expected, active_group remains the top performer in this scenario, given the absence of any work. However, active_obj emerges as the least favorable option due to the huge number of workers that causes overhead of thread oversubscription. Also, an intense contention between the sender and the receivers makes things worse. VTune analysis confirms that this issue accounts for most of the CPU time (approximately 99%) and that effective CPU utilization is really poor:
Now we add a little sleep to agent’s handler to simulate some non-CPU work:
In this scenario, maximizing the number of agents that sleep simultaneously seems to be the most effective strategy for reducing time. As a result, active_obj emerges as the winner, since it allows multiple agents to sleep concurrently. In contrast, active_group and thread pools with cooperation FIFO are unable to set sleeping threads. A thread pool with individual FIFOs can roughly allow four threads to sleep simultaneously, thereby reducing the total time approximately by a factor of four. In this case, max_demands_at_once does not influence the results.
The last test consists in making agents use the CPU a bit. A simple way to achieve this consists in calling a mathematical computation such as std::sph_neumann(). The function is very fast but we hope the CPU usage will be higher when invoked in parallel:
class performer final : public so_5::agent_t
{
public:
// ... as before
void so_define_agent() override
{
so_subscribe(m_input).event([this](unsigned msg) {
series += sph_neumann(msg, 1.2345);
if (--m_message_count == 0)
{
so_5::send<unsigned>(m_output, m_worker_id);
}
});
}
private:
// ... as before
double series = 0.0;
};
First of all, we time only sending with message_count=100’000 and workers_count=10:
Essentially, the performance of so_5::send is influenced by both the number of subscribers and the type of dispatcher they are bound to. The dispatcher determines the number of event queues the sender must push events to, as well as the number of threads that will compete for such queues.
In the case of 100 workers, both active_group and the thread pools maintain the same number of threads as the previous case with 10 workers. Thread pool with individual FIFO creates one queue per agent but the contention is still with 4 threads. On the other hand, active_obj spawns a thread and a queue per agent, resulting in a much more significant queue contention than before.
Indeed, it’s important to consider that senders can be influenced by factors beyond their control, such as the number of subscribers (and their dispatchers) to the channels they send data to, as well as message limits, filters and message chains overflow strategies we discussed in previous posts.
Now, we launch the benchmark with these parameters – still a relatively small number of agents:
In this case, active_obj is still the winner, as the operation is highly parallelizable, and the number of workers is contained. Allocating one dedicated thread per agent is managed well by the operating system despite the oversubscription (clearly, the CPU usage is quite intense, with peaks of ~80% usage overall, consuming ~700MB of memory).
On the other hand, active_group does not parallelize at all, likewise thread pools without cooperation FIFO. On the other hand, a thread pool with 16 threads and individual FIFO shows performance comparable to active_obj but resulting in less oversubscription.
Another interesting variation of this setup consists in configuring a high number of workers (10’000) but a small number of messages (100) and see the differences between individual thread pools and active_obj:
As expected, active_obj is a suboptimal choice as the number of workers is too high.
These considerations highlight that we should take active_obj with a grain of salt. Ideally, dedicating one thread per agent is the simplest design choice but it might have important performance implications, as we have just seen.
Observing the bulk effect
The final benchmark we’ll briefly discuss in this article is a variation of the previous one: instead of data being produced by a centralized producer, we have agents that send messages to themselves until a certain number of messages is processed. Once completed, they send a notification to the “master” agent. Each worker sends several messages to itself right after the start and this parameter will be configurable. Thus, the agents work independently from each other:
The purpose is to highlight the overhead on the service of a large number of queues on dispatchers with thread pools. Differently from the previous scenario, in this case the contention on the same queue is insignificant.
The code is here below:
template<unsigned workers_count>
class master final : public so_5::agent_t
{
public:
master(so_5::agent_context_t c)
: agent_t(std::move(c))
{
}
void so_define_agent() override
{
so_subscribe_self().event([this](unsigned worker_id) {
m_done_received[worker_id] = true;
if (m_done_received.all())
{
so_environment().stop();
}
});
}
private:
std::bitset<workers_count> m_done_received;
};
class worker : public so_5::agent_t
{
struct self_signal final : so_5::signal_t {};
public:
worker(so_5::agent_context_t c, unsigned message_count, unsigned start_batch, unsigned worker_id, so_5::mbox_t dest)
: agent_t(std::move(c)), m_message_count(message_count), m_start_batch(std::max(1u, start_batch)), m_worker_id(worker_id), m_output(std::move(dest))
{
}
void so_evt_start() override
{
for (auto i=0u; i<m_start_batch; ++i)
{
so_5::send<self_signal>(*this);
}
}
void so_define_agent() override
{
so_subscribe_self().event([this](so_5::mhood_t<self_signal>) {
if (--m_message_count != 0)
{
so_5::send<self_signal>(*this);
}
else
{
so_5::send<unsigned>(m_output, m_worker_id);
}
});
}
private:
unsigned m_message_count;
unsigned m_start_batch;
unsigned m_worker_id;
so_5::mbox_t m_output;
};
TEST(benchmarks, self_send)
{
constexpr auto workers_count = 50;
constexpr auto message_count = 1000000;
constexpr auto start_batch = 1;
const auto tic = std::chrono::steady_clock::now();
so_5::launch([](so_5::environment_t& env) {
env.introduce_coop([&](so_5::coop_t& coop) {
const auto master_mbox = coop.make_agent<master<workers_count>>()->so_direct_mbox();
const auto thread_pool = make_dispatcher(env, "workers",
so_5::disp::thread_pool::disp_params_t{}
.thread_count(16))
.binder(so_5::disp::thread_pool::bind_params_t{}.
fifo(so_5::disp::thread_pool::fifo_t::individual)
.max_demands_at_once(1)
);
for (auto i = 0u; i < workers_count; ++i)
{
coop.make_agent_with_binder<worker>(thread_pool, message_count, start_batch, i, master_mbox);
}
});
});
const auto elapsed = std::chrono::duration<double>(std::chrono::steady_clock::now() - tic).count();
std::cout << std::format("self-send (message_count={} worker_count={}) elapsed={}\n", message_count, workers_count, elapsed);
}
The interesting part of this benchmark is the effect of varying max_demands_at_once to observe the so-called bulk effect (or batch effect). In essence, in presence of a dense flow of events, a thread that processes more messages from a queue instead of frequently switching to other queues might improve performance. Indeed, with these parameters:
workers_count=50
message_count=1M
start_batch=1
The test shows different values of elapsed time depending on max_demands_at_once:
16 threads and max_demands_at_once=100 takes 0.9673126s
4 threads and max_demands_at_once=100 takes 1.6485941s
4 threads and max_demands_at_once=4 takes 3.2874836s
16 threads and max_demands_at_once=4 takes 4.3633599s
4 threads and max_demands_at_once=1 takes 9.8537081s
16 threads and max_demands_at_once=1 takes 16.267653s
max_demands_at_once=4 is mentioned because it’s the default value. The interpretation of these numbers is clear: when threads minimize switching while processing “hot” queues, the overall performance improves.
When increasing the number of workers and the start batch:
workers_count=1’000
message_count=1M
start_batch=100
The bulk effect is consistent:
16 threads and max_demands_at_once=50’000 takes 16.383999s
16 threads and max_demands_at_once=10’000 takes 16.48325301s
16 threads and max_demands_at_once=1’000 takes 17.2395806s
16 threads and max_demands_at_once=100’000 takes 17.7065044s
16 threads and max_demands_at_once=100 takes 19.4542036s
16 threads and max_demands_at_once=4 takes 80.6875612s
16 threads and max_demands_at_once=1 takes 81.2743937s
For this specific setup, the optimal value for max_demands_at_once is around 50,000, while 100,000 performs slightly worse than 1,000. The worst performer is 1, as the CPU constantly switches threads from one queue to another. Considering that each handler enqueues a new event into the same queue, the processing thread is guaranteed to find at least max_demands_at_once events to process. However, the drawback is the risk of starvation: once an agent is selected for processing, it monopolizes the worker thread for max_demands_at_once events.
Thus, max_demands_at_once is an important setting that might give very different performance results when dealing with a dense flow of events.
Final remarks
Exploring performance indicators and conducting typical benchmarks provides valuable insights into the costs and optimization options within SObjectizer and other actor frameworks. Through these investigations, we’ve gained a deeper awareness of various factors that influence system performance, including message passing overhead, agent management costs, and the impact of different dispatcher configurations. Armed with this knowledge, we can fine-tune applications to achieve optimal performance while meeting their specific requirements and constraints.
Numerous other benchmarks and performance tests remain unexplored, but now you should possess more tools to gain further insights into the topic. For instance, you could investigate the performance of message chains or compare the efficiency of using adv_thread_pool versus manually distributing work across multiple agents.
Our exploration of performance considerations is not yet complete. In a forthcoming post, we will continue this journey by examining additional components provided by SObjectizer that enable us to gather additional metrics and indicators while the application is running.
Takeaway
In this episode we have learned:
typical actor framework benchmarks include agent management (creation and destruction), 1:1 and 1:N messaging, and impact of using multiple thread configurations;
agent management has been evaluated through skynet, assessing the performance of agent creation and destruction. While managing thousands of agents is typically insignificant, creating and destroying one million agents might be something to avoid;
1:1 messaging has been benchmarked using ping-pong, a typical test measuring message exchange between two agents;
1:N messaging has been demonstrated by one producer and multiple consumers subscribed to the same channel, akin to calico‘s scenario;
we demonstrated that using active_obj dispatcher is a suboptimal choice when the number of agents is too high;
we observed the performance of sending data is influenced by factors beyond its control such as the number of receivers and the dispatchers in use;
we also observed the bulk (batch) effect in a variation of the above-mentioned benchmark;
so_5::launch is a self-contained function to instantiate, launch and keep alive a SObjectizer environment until explicitly stopped;
thread_pool dispatcher’s max_demands_at_once setting determines how many events from a queue the thread has to process before switching to another queue;
in case of dense event flow, incresing max_demands_at_oncemight result in better performance as the bulk effect is effectively handled.
As usual, calico is updated and tagged. In this regard, we have two considerations: first of all, the actual implementation of benchmarks in calico is slightly more “generalized” than that presented in this post as here we favored simplicity for the sake of explanation. Secondly, since come benchmarks take a while, you will find them all disabled. To run calico_tests executing benchmarks, add the command line option:
--gtest_also_run_disabled_tests
For example:
calico_tests.exe --gtest_also_run_disabled_tests
By the way, please consider these benchmarks do not pertain to calico but are added in its suite for simplicity and to let you play with them without the bother of creating a new project.
What’s next?
As our discussion with Helen regarding performance comes to a close, she remains interested in understanding how service_time_estimator_dispatcher can avoid copying execution_demand_t instances while making modifications during processing. Is this a general feature or an isolated case?
In the upcoming post, we’ll learn a new feature of SObjectizer pertaining to 1:1 messaging that allows us to exchange “mutable” messages.
In the previous episode we introduced a simple but effective model to characterize the performance of a single actor:
In particular, we explored throughput as a key indicator and we discussed that it’s influenced by the other factors:
arrival rate: how fast messages to process arrive;
waiting time: how fast messages in the queue are handed over to the agent;
service time: how fast messages are processed by the agent.
We also mentioned that latency is the sum of waiting time and service time.
In essence, to increase throughput, we can adjust these parameters or try scaling the system by distributing work across multiple agents (or threads).
Throughput can be monitored over time, as demonstrated with fps_estimator, and benchmarked in isolated tests, as demonstrated with frequency_calculator. When this indicator becomes a concern, gathering additional information about the system becomes important. Firstly, it’s worth thinking of which entities come into play in SObjectizer to influence the above-mentioned parameters:
arrival rate is actually determined by the system (meaning, for example, by the requirements of the problem to solve or by the data sources – e.g. the camera) and might be influenced by facilities executed at the sender site such as filters (as mentioned in a previous post, slow filters cause slow sending, possibly resulting in a worse arrival rate);
service time is defined by the agent but it can be indirectly influenced by other factors (e.g. CPU contention might have an impact, as seen in the previous post);
waiting time is mostly determined by the dispatcher, which is responsible for dequeuing a message and executing an agent’s handler for that on a specific thread. However, it’s evident that waiting time may also be indirectly influenced by service time because messages, unless processed by thread-safe handlers, will be handled sequentially by an agent. The longer the service time, the longer the wait to handle the next message.
Moreover, there are scenarios where we can actually distribute work across multiple workers. In this context, when there is an observed increase in overall throughput, it is likely due to a reduction in waiting time rather than service time (which may even be prolonged when the contention of the CPU is significant). Put simply, the time required to dequeue N messages will decrease but time to handle one will not. In this case, it’s common to say that the latency decreased (as we have seen, throughput and latency go together).
When increasing throughput by distributing work is not feasible, we typically turn our attention to waiting time and service time. However, since waiting time is not likely under our control, it is more useful and simple to initially gain an understanding of service time.
The most favorable situation to measure service time is when the logic is outside the agent. While this may seem like an obvious observation, there are scenarios where we begin with legacy code and migrate certain parts to agents, or we utilize functions and classes that already exist outside agents and have been tested in isolation already. For instance, in the case of the face_detector, since the face recognition routine is quite standard, the core logic could possibly be outside the agent. In this case, to measure the service time we would simply measure the performance of that function.
However, this is not really the case for agents such as image_resizer and face_detector as the logic is totally inside such agents. After all, the actor model is conceived to encapsulate logic within agents and refer threading and messaging to the framework. What to do in this case?
In this article, we will explore a technique to measure the service time of agents in isolation. This approach should be used in tests only and it’s different from another “monitoring” tool provided by SObjectizer that will be discussed in a future post.
Where the measure should be placed
As said, service time is the measure of the agent’s reaction to a specific message, without considering waiting time. For example, measuring service time of image_resizer, ideally would be equivalent to this:
This measurement might be taken multiple times, and the average used as a reference.
A non-intrusive approach to extract this metric requires us to enter a bit more into some internals of SObjectizer. We know that the entity responsible for executing an agent’s message handler on a viable worker thread is the dispatcher. A dispatcher also manages message queues for agents that are bound to it. This is an important distinction of SObjectizer from other actor frameworks: a message queue does not belong to an agent; rather, it is created and managed by a dispatcher. Another differentiating factor of SObjectizer from other actor frameworks is the number of message queues. In the “classical” actor-based approach, each actor has its own queue for processing messages. In SObjectizer, a dispatcher chooses how many queues are required to serve agents bound to that dispatcher. It’s an implementation detail.
In other words, a dispatcher is responsible for:
creation and deletion of worker threads;
creation and deletion of message queues;
extraction of messages from queues and invocation of message handlers in the context of dispatcher’s working threads.
The last point hints that dispatchers might be the entity where we can place code time message handlers execution. Is that correct?
Commonly speaking, yes. Formally, we need to grasp a few more details.
After an agent is created, it is bound to a message queue. This fact determines the actual start of its work. Messages directed to the agent are pushed to that queue and eventually extracted to be handled on a certain thread. As we have learnt, this is the dispatcher’s job. How is the dispatcher bound to the agent? In the series, we mentioned the “dispatcher binder” is responsible for this purpose. For example:
env.introduce_coop(so_5::disp::active_obj::make_dispatcher(env).binder(), [](so_5::coop_t& c) {
// ...
});
The one million question is: does make_dispatcher return a concrete class implementing a sort of “dispatcher interface”? Somehow. It returns a dispatcher_handle_t that is just a wrapper around a dispatcher binder. The dispatcher binder provides such an interface, in particular it exposes a function that binds an agent to a message queue (formally, an “event” queue) that provides an interface for “pushing a message”. Thus, strictly speaking there is no “dispatcher” interface to implement. Instead, there are two interfaces that are commonly implemented to create a custom dispatcher:
dispatcher binder (disp_binder_t)
event queue (event_queue_t)
The dispatcher binder serves as the interface that allows binding an agent to a customized event queue. The event queue, in turn, is the interface that describes how events are stored for handling. In the SObjectizer slang, the term “dispatcher” commonly refers to the bunch of implementation details that connect these elements behind the scenes. It’s the strategy responsible for dequeuing events from the queue and enabling their execution on a certain thread. Practically speaking, this usually requires us to develop both a custom dispatcher binder and a custom event queue. Things will be clearer once we get to the implementation.
The good news is that the complete code for our “dispatcher” is quite short and can serve as a starting point in case you want to roll your own dispatcher. There are a few new concepts of SObjectizer we’ll meet and discuss along the way.
Service time estimator dispatcher
Our attention needs to be directed towards the purpose of this “service time estimator dispatcher”. The objective is to isolate the portion of code where an agent’s handler is invoked and measure the time taken for that invocation. Possibly, we set the number of expected messages and calculate the average service time taken to process them all. We can ignore any thread_safe marker. Also, as the dispatcher should be used in isolated tests only, we can assume it will be bound to a single agent only.
The approach will be simple and self-contained: we launch a single worker thread that dequeues and invokes all the events one by one. Since we do have control, we time the code portion that invokes the handler.
There are a few details we need to decide:
where to store events?
should we distinguish start/finish events from others?
how to manage the worker thread?
The responses to these questions may differ, but we can adhere to straightforward yet impactful decisions:
we use message chains;
yes, we should distinguish start/finish events because we don’t need to measure them;
we can use std::jthread.
As said, we need to implement both an event queue and a dispatcher binder. The former will serve to – literally – push events to our designated data structure (a message chain), the latter will serve to – literally – bind any agent to our message queue. For simplicity, we implement both the interfaces into the same class, but this is not required in general.
The custom event queue
The first part of our implementation contains the definition of the functions declared in the event_queue_t interface:
push(execution_demand_t)
push_evt_start(execution_demand_t)
push_evt_finish(execution_demand_t) noexcept
In other words, these functions enable us to customize how (and where) events are stored when they are transmitted from a sender (e.g. so_5::send) to a receiver (e.g. an agent) that is bound to our event queue. The particular execution_demand_t represents an event ready to be executed, encapsulating all its information, including the agent, the message limit, the message box, the message type, the message payload and, finally, the event handler that can be called.
An important observation: if any event is pushed to the event queue, it means all the filtering and limiting stuff has been done already by SObjectizer. Pushing an event to the queue is like saying “this event must be delivered to the agent”. The agent then will eventually either handle the message or discard it if the agent does not process this type of message in the current state (however, this check is its responsibility and it’s done by SObjectizer behind the scenes). Also, we don’t really need to deal with all the above-mentioned information to execute the event handler. Instead, we can just call this function:
We have opted to employ message chains for storing our events, distinguishing between two types: one for “ordinary” events and a dedicated chain for start and stop events. This approach allows the dequeue strategy to differentiate between the two flavors:
At this point, we expect that somehow we have a worker thread that dequeues events and executes the execution_demand_t instances as we have already introduced before:
demand.call_handler(thread_id);
The custom dispatcher binder
Next, we put our hands on the dispatcher binder interface that consists of these functions:
preallocate_resources(agent_t&)
undo_preallocation(agent_t&) noexcept
bind(agent_t&) noexcept
unbind(agent_t&) noexcept
Without delving into unnecessary details, these functions primarily serve the purpose of assigning the event queue (e.g. our custom event queue) to an agent and, in case, providing the customization points for preallocating resources (e.g. a thread pool) and cleaning up. In case of troubles with the cooperation registration, possible preallocated resources can be cleaned up with undo_preallocation() that would be called. Also, unbind() is called when the cooperation gets deregistered. From our side, we only need to customize bind() so we’ll leave the others empty:
At this point, we simply need to spawn the worker thread responsible for dequeuing and processing events. We do that in the constructor, together with the creation of both the message chains:
class service_time_estimator_dispatcher : public so_5::event_queue_t, public so_5::disp_binder_t
{
public:
service_time_estimator_dispatcher(so_5::environment_t& env)
: m_event_queue(create_mchain(env)), m_start_finish_queue(create_mchain(env))
{
m_worker = std::jthread{ [this] {
// ... process
} };
}
// ... as before
private:
std::jthread m_worker;
so_5::mchain_t m_event_queue;
so_5::mchain_t m_start_finish_queue;
};
Now there is an interesting feature of SObjectizer we can leverage: receiving from multiple message chains within the same statement. Indeed, the worker thread might receive both ordinary and start/finish events. In essence, instead of using receive, we use select + receive_case that are two ergonomic features of SObjectizer for receiving from message chains. The code speaks for itself:
This allows it to receive simultaneously from several message chains until they are closed. Every receive_case should contain all the relevant handlers for a given chain. However, if the same message chain is used in multiple receive_case statements, the behavior is undefined.
We have finally reached our target! In fact, we can profile and execute every execution demand in the receive_case of m_event_queue:
Since execution_demand::call_handler() needs a thread id, we simply retrieved and used that of the worker thread. At this point, we implement the above-mentioned feature of this dispatcher: calculating the average elapsed times over an expected number of measures. This can be done in many different ways, we propose one that accumulates the elapsed times and eventually calculates the average by dividing that number by the expected measure counter. To communicate results to the outside, we pass an output channel to the dispatcher (some frameworks provide predefined channels for this stuff, such as Akka’s EventStream).
However, this implementation has a subtle bug spotted by Yauheni: in essence, dispatchers must guarantee that the start event is delivered before every other message and that after the finish event no other messages are dispatched to the agent. This implementation does not really guarantee these two conditions because data can arrive to the input channel of an agent even before it’s bound to the event queue. As Yauheni pointed out while reviewing this article:
the agent subscribes to some messages in so_define_agent (at that moment the agent is not yet bound to the event queue);
the agent is bound to the event queue and the start event demand is stored into the special message chain. But the select doesn’t yet waked up;
a message is sent to the agent at this moment. Since the agent is bound to the event queue, the message will be stored in ordinary message chain;
the dispatcher finally wakes up and executes select(). A demand from the ordinary message chain is extracted first, and only then the start event demand.
Thus, there exist several ways to solve this problem. Since Yauheni suggested three different versions, we present here that we think it’s the most interesting. Basically, we get rid of select and split reception on the two types of message chains:
m_worker = std::jthread{ [this] {
const auto thread_id = so_5::query_current_thread_id();
// Step 1. Receive and handle evt_start.
receive(from(m_start_finish_queue).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
d.call_handler(thread_id);
});
// Step 2. Handle all ordinary messages until m_event_queue is closed.
receive(from(m_event_queue).handle_n(messages_count), [thread_id, this](so_5::execution_demand_t d) {
const auto tic = std::chrono::steady_clock::now();
d.call_handler(thread_id);
const auto toc = std::chrono::steady_clock::now();
const auto elapsed = std::chrono::duration<double>(toc - tic).count();
});
// Step 3. Receive and handle evt_finish.
receive(from(m_start_finish_queue).handle_n(1), [thread_id, this](so_5::execution_demand_t d) {
d.call_handler(thread_id);
});
} };
In addition, as noted by Yauheni, there is another interesting side-effect in this approach: m_event_queue_start_stop can hold no more than 2 demands, this means we can use a fixed-size chain with preallocated storage. We don’t do this now but it was worth sharing.
The full implementation is here below (we have just added the total average calculation and sending, after receiving all the messages in the intermediate step):
The last missing thing is how to create this instance and pass it to the cooperation. Well, the idiomatic way consists in adding a static factory function into the dispatcher:
We can finally create a new test using our dispatcher:
TEST(performance_tests, image_resizer_service_time)
{
constexpr unsigned messages_count = 1000;
so_5::wrapped_env_t sobjectizer;
auto& env = sobjectizer.environment();
auto input_channel = env.create_mbox();
auto output_channel = env.create_mbox();
const auto measure_output = so_5::create_mchain(env);
const auto measuring_dispatcher = service_time_estimator_dispatcher::make(env, measure_output->as_mbox(), messages_count);
env.introduce_coop(measuring_dispatcher, [&](so_5::coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel, 4);
});
const auto test_frame = cv::imread("test_data/replay/1.jpg");
for (auto i = 0u; i < messages_count; ++i)
{
so_5::send<cv::Mat>(input_channel, test_frame);
}
receive(from(measure_output).handle_n(1), [](double service_time_avg) {
std::cout << std::format("image_resizer average service time calculated on {} frames is: {}s\n", messages_count, service_time_avg);
});
}
On my machine (Intel i7-11850H @2.50GHz, 8 Cores), this test consistently outputs between 0,00099s (<1ms) and 0,0011s (1.1ms), that is aligned with a maximum throughput of ~900 fps we measured in the previous post (remember that the calculation of the maximum throughput includes other costs such as sending and waiting time).
Take into account that the method for calculating the average service time is simplistic and may not be suitable in certain cases. Nevertheless, given that you are now aware of where the measurement can occur, you can employ other approaches to make this measurement.
An implementation detail
When I showed this dispatcher to Yauheni for the first time, he got back to me with a main point: “you’ll have a copy of execution_demand_t on every call. Because execution_demand_t is not a small object (it holds 3 raw pointers, a std::type_index, 64-bit mbox_id_t and reference-counting message_ref_t) the copying can have an impact on the performance”. He was pointing to this part:
Since execution_demand_t::call_handler() is non-const, we need a copy of the execution_demand_t to invoke that function.
Certainly, as this dispatcher is primarily used for measuring service time in a test bench, our focus is not on micro-optimization. Nonetheless, Yauheni’s suggestion is useful to introduce another feature of SObjectizer which we’ll delve into in a future post to avoid taking on too much at once.
Service time with multiple threads
In the previous post we mentioned that distributing image_resizer‘s work across multiple workers degrades performance a bit because of the contention of the CPU, since cv::resize is already trying to exploit several cores.
Can we observe this issue on the service time?
Partially. We can only see the effect of multiple image_resizer instances executing their logic (that is mainly cv::resize) simultaneously. The test with two agents is performed by instantiating two cooperations that use two different instances of our new dispatcher:
TEST(performance_tests, two_image_resizers_in_parallel)
{
constexpr unsigned messages_count = 100;
so_5::wrapped_env_t sobjectizer;
auto& env = sobjectizer.environment();
auto input_channel = env.create_mbox();
auto output_channel = env.create_mbox();
auto measure_output1 = so_5::create_mchain(env);
auto measure_output2 = so_5::create_mchain(env);
env.introduce_coop(service_time_estimator_dispatcher::make(env, measure_output1->as_mbox(), messages_count), [&](so_5::coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel, 4);
});
env.introduce_coop(service_time_estimator_dispatcher::make(env, measure_output2->as_mbox(), messages_count), [&](so_5::coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel, 4);
});
const auto test_frame = cv::imread("test_data/replay/1.jpg");
for (auto i = 0u; i < messages_count; ++i)
{
so_5::send<cv::Mat>(input_channel, test_frame);
}
receive(from(measure_output1).handle_n(1), [](double service_time_avg) {
std::cout << std::format("image_resizer(1) average service time calculated on {} frames is: {:.5f}s\n", messages_count, service_time_avg);
});
receive(from(measure_output2).handle_n(1), [](double service_time_avg) {
std::cout << std::format("image_resizer(2) average service time calculated on {} frames is: {:.5f}s\n", messages_count, service_time_avg);
});
}
As you see, even though we send test frames only to input_channel, each agent receives its own copy of that instance. This is not equivalent to distributing the input images across multiple workers since, in that case, every frame would be processed by exactly one worker.
Yet, we get a qualitative idea of the situation and, indeed, on my machine I obtain interesting results:
image_resizer(1) average service time calculated on 100 frames is: 0.00201s
image_resizer(2) average service time calculated on 100 frames is: 0.00219s
In simpler terms, the service time of the two agents in this test is approximately twice the service time of the agent in the single-threaded test. This suggests that CPU contention and context switching are somewhat confirmed by this qualitative experiment. However, it’s important to note that this only arouses our suspicions, opening the door to further investigations. It’s not a comprehensive profiling.
Final remarks
The presented approach only works when we need to measure the average time to react to a certain message by an agent. Indeed, a dispatcher works by dequeuing events and executing handlers. However, it does not work, for example, if the agent is stuck in a blocking receive like image_saver_worker:
In this scenario, the dispatcher solely executes the “start event” which will lead the executing thread to be blocked until the receive operation is completed, presumably during the shutdown.
After all, service_time_estimator_dispatcher is effective only when events are naturally handled by the agent under test. In essence, SObjectizer can’t be of much help if events can’t be “sampled”.
In cases such as image_saver_worker, one intrusive option is to include profiling information into the agent, possibly under some configuration toggle. Another approach, if feasible, involves refactoring the agent to decouple the reception and handling of messages. This allows for the reestablishment of a flow of events that can be sampled more naturally.
Another point worth mentioning is that measuring service time in isolation is typically necessary only to benchmark the optimal performance of a specific operation, helping to understand if certain requirements can be technically satisfied in relation to a target throughput. For example, if a certain agent is required to process at rate of 50 fps, either its service time should not be higher than 20 milliseconds on average or we find a work distribution schema that makes the target throughput sustainable. However, in a real system, as we have seen, the actual performance of what was measured in isolation can vary substantially due to several factors, including the contention for the same set of computational resources and context switching. Additionally, performance requirements are generally set on the whole pipeline rather than on specific agents.
There is also another indicator that we have somewhat ignored: waiting time. As mentioned earlier, waiting time mainly depends on the dispatcher. When service time is not a concern but throughput is suspiciously below expectations, waiting time might be investigated. Sometimes, this leads to tuning or replacing the dispatcher, or even – as a drastic decision – rolling out a custom implementation. This is relevant in SObjectizer as it differs from other frameworks: multiple agents can share the very same message queue, or one agent can have its messages hosted on multiple queues. Also, the threading strategy varies. It all depends on the dispatcher. Thus, the waiting time of each message is influenced by how agents are bound to dispatchers.
By knowing throughput and service time we can approximate waiting time, however the exact calculation should be done inside the dispatcher. Technically speaking, waiting time is the difference between the moment a message is pushed to the queue and the moment it’s dequeued, just before executing the corresponding handler. However, SObjectizer does not provide this calculation within its dispatchers.
Takeaway
In this episode we have learned:
service time represents how fast messages are processed by the agent;
to calculate service time in isolation, an approach consists in rolling out a custom dispatcher that enables us to time the execution of an event handler;
this approach only works when handling of messages is done through agent subscriptions as events must be “sampled” by the dispatcher;
commonly in SObjectizer, a dispatcher is the combination of an event queue and a dispatcher binder. To implement these two, we must implement two interfaces;
a custom event queue must implement event_queue_t and defines the strategy to accumulate new events to be processed;
a custom dispatcher binder must implement disp_binder_t and its main role is to bind an agent to an event queue (e.g. the custom event queue);
the rest of the details should define how events are dequeued from the event queue and processed, by executing handlers on some thread (e.g. a single thread, a thread pool);
select + receive_case is an idiom to receive from multiple message chains within the same statement;
a message chain can’t appear in more than onereceive_case, otherwise the behavior is undefined;
typically, measuring service time in isolation is useful to benchmark the optimal performance of a specific operation, however the number may vary when calculated within the real system;
waiting time is another metric that might be useful to investigate if the dispatcher in use fits our needs, however it can only be approximated.
In the upcoming article, our discussion with Helen about performance will wrap up as we delve into typical benchmarks for actor frameworks and share some experiments conducted with SObjectizer.
Transmitting a message from one agent to another is not nearly as fast as one object invoking a method on another object within the same process. While the latter involves a few highly optimized processor instructions, the former necessitates a multitude of processor instructions in comparison.
However, the actor model doesn’t strive to compete at the level of single invocations. The traction for that paradigm has increased due to the contemporary need for massively parallel computing applications. Indeed, a key aspect of the actor model’s appeal lies in its capacity to express unbounded parallelism. Its emphasis on message passing, isolation of state, and decentralized control makes it suitable for developing concurrent applications by simplifying common challenges associated with multithreading.
As we have learnt, the actor model provides a high-level abstraction where actors – or agents – communicate through messages, allowing us to focus on the logic without dealing with low-level thread management nor with message delivery mechanics that are referred to the framework. Programs can be scaled by distributing agents across multiple threads, making this paradigm well-suited for applications with varying workloads. In the general actor model, the distribution can also happen across other processes and machines.
However, if the performance of our system falls short of the requirements, we simply want to prevent performance regressions over time, or we need to assess and fine-tune applications then we should extract and keep track of performance metrics.
An important premise to consider is that measuring and observing performance in software is challenging. Applications often run in diverse environments with varying hardware, operating systems, and configurations, making it difficult to establish standardized measurements. Additionally, external applications, either directly or indirectly, can have an impact, resulting in less deterministic tests and benchmarks.
This three-part full-immersion provides a friendly introduction to performance metrics and considerations in message-passing styled applications, with a specific emphasis on SObjectizer and the in-process actor model. Additionally, we will explore key factors that framework developers often benchmark for comparative analysis with other frameworks.
It’s essential to note we won’t address the broader subject of measuring software performance “in general” or when a system is distributed across multiple processes and machines.
Performance model
A well-known model to represent the performance characteristics of a single actor is presented in Akka in Action, applied here below to our face_detector:
In essence, it consists of a few metrics:
the arrival rate is the number of messages (e.g. images) to process during a period, usually expressed in a common time unit (e.g. 30 frames per second – 30 fps);
the throughput is the number of processed messages during a period, usually expressed in a common time unit (e.g. 15 fps);
the waiting time is the time one message spends in the queue before being handled (e.g. 1 microsecond);
finally, the service time is the time needed to handle one message (e.g. the time needed by face_detector to recognize faces on a single frame).
While throughput is commonly linked to the “output of messages,” its significance extends beyond that and is applicable to “sink” agents that do not produce messages. For instance, the image_saver has a specific throughput, representing the number of images saved to disk per second, even though it does not generate outputs.
Frequently, the term “service time” is interchangeably used with another concept you might be more acquainted with: latency. To be precise, latency is equivalent to the sum of service time and waiting time. In simpler terms, it represents the duration it takes for a message to be processed from the moment it is sent to the agent’s queue to the moment it’s fully processed and, possibly, dispatched to another channel. It’s worth bringing into focus that in SObjectizer waiting time primarily depends on the dispatcher, whereas service time is determined by the agent.
Throughput and latency, much like jelly and peanut butter, go hand in hand and define the two primary categories of performance issues in such systems: either the throughput is too low, or the latency is too high. While boosting throughput can often be addressed through scaling, such as introducing more workers, addressing latency issues typically necessitates more fundamental changes, like adopting a different algorithm. Indeed, when dealing with a performance issue, tuning often involves a trade-off. To enhance the performance of an agent, we typically have three potential courses of action:
increasing the number of workers to distribute work horizontally (e.g. using multiple instances of the same agent or executing agent’s handlers on multiple threads – as explained in the previous post);
decreasing the arrival rate of messages to be processed;
reducing the service time.
The most straightforward action, when feasible, is to increase the number of workers. This proves effective when throughput is a concern, and contending for CPU power does not adversely impact overall performance. The second strategy involves reducing the arrival rate, but this may not always be practical and might require altering the system’s design. In such scenarios, filtering can provide a potential help. The last approach is often challenging to implement and involves redesigning the functionality to decrease the time it takes for an agent to execute it.
Thus, the presented model, while straightforward, is sufficient for observing major issues during runtime. The optimal scenario occurs when arrival rate and throughput are nearly identical, indicating that the agent does not buffer, and the waiting time is minimal, approaching zero. On the flip side, if the throughput significantly lags behind the arrival rate, the agent will start buffering messages, introducing potential issues that were discussed when we delved into the realm of limiting message flow (another indicator of such problems is the agent’s queue size: when that number grows, it means that the actor is saturated).
So the first action we can take to monitor the system’s health consists in observing throughput.
Observing throughput
Often, throughput stands out as the pivotal metric, serving as a crucial indicator of the system’s sustainability from a load standpoint. Insufficient throughput prompts the need for further actions, such as investigating and optimizing service time, increasing the number of agents handling resource-intensive tasks, or even simplifying the system.
Although every performance-critical agent might be instrumented – even under specific configuration toggles – to provide performance metrics, introducing an agent that simply estimates the throughput on a certain channel over time might be useful. Imagine the following topology:
We introduce an “fps estimator” agent whose sole function is to estimate the number of frames transmitted to a specific channel over time:
Above, we are simply estimating the throughput of image_producer (that is the arrival rate of image_resizer) and, ultimately, the throughput of the face_detector (that is the arrival rate of image_viewer). Ideally, there should be consistency in values of the initial and the second fps estimator. Conversely, if these values differ considerably, introducing additional estimators into the intermediate stages can help pinpoint and narrow down the source of the problem.
This approach resembles the process of measuring energy consumption at home with commercial “energy meters”:
The sole semantic distinction lies in the fact that these devices function as “adapters,” rerouting “electricity” to the other side. Achieving a similar outcome could involve having the “fps estimator” redirect input images to an output channel. However, this is unnecessary since multiple agents can subscribe to the same channels — conversely, multiple devices can’t be connected to the very same electric socket.
The implementation of such estimator boils down to counting the number of frames received over a fixed time span and dividing such number by the elapsed time. This measure is performed and logged at regular intervals, such as 5 seconds but might vary statically or dynamically:
Let’s use this agent to measure the frame rate on both the main channel and the face detector’s output channel:
int main()
{
const auto ctrl_c = get_ctrlc_token();
const so_5::wrapped_env_t sobjectizer;
const auto main_channel = sobjectizer.environment().create_mbox("main");
const auto commands_channel = sobjectizer.environment().create_mbox("commands");
const auto message_queue = create_mchain(sobjectizer.environment());
sobjectizer.environment().introduce_coop(so_5::disp::active_obj::make_dispatcher(sobjectizer.environment()).binder(), [&](so_5::coop_t& c) {
c.make_agent<image_producer_recursive>(main_channel, commands_channel);
c.make_agent<maint_gui::remote_control>(commands_channel, message_queue);
const auto resized = c.make_agent<image_resizer>(main_channel, 0.5)->output();
const auto decorated = c.make_agent<face_detector>(resized)->output();
c.make_agent<fps_estimator>(main_channel);
c.make_agent<fps_estimator>(decorated);
});
do_gui_message_loop(ctrl_c, message_queue, sobjectizer.environment().create_mbox(constants::waitkey_channel_name));
}
A possible output follows:
Estimated fps @<mbox:type=MPMC:id=12>=~0.00 (0 frames in ~5s)
Estimated fps @main=~0.00 (0 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~15.00 (75 frames in ~5s)
Estimated fps @main=~15.00 (75 frames in ~5s)
Estimated fps @main=~20.41 (102 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~20.20 (101 frames in ~5s)
Estimated fps @main=~29.79 (149 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~30.00 (150 frames in ~5s)
Estimated fps @main=~29.80 (149 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~29.81 (149 frames in ~5s)
Estimated fps @main=~29.81 (149 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~29.81 (149 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~29.80 (149 frames in ~5s)
Estimated fps @main=~29.79 (149 frames in ~5s)
Estimated fps @main=~15.41 (77 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~15.40 (77 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~0.00 (0 frames in ~5s)
Estimated fps @main=~0.00 (0 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~0.00 (0 frames in ~5s)
Estimated fps @main=~0.00 (0 frames in ~5s)
When the stream is disabled, the frame rate is evidently zero. Upon initiating the acquisition, frames begin to flow, and the frame rate gradually increases until it stabilizes at a more constant value (around 30 in this example). The agent could be extended to measure the frame rate of multiple channels simultaneously, offering the advantage of obtaining more consistent results over time:
Sometimes, it is beneficial to enable this log only during active streaming and not when the acquisition is inactive. In such cases, we can utilize states, as discussed in a previous post for stream_heartbeat:
This approach ensures a consistent measurement over the same time frame, and specifically, only when the stream is actively ongoing:
Estimated fps @<mbox:type=MPMC:id=12>=~30.00 (150 frames in ~5s)
Estimated fps @main=~29.99 (150 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~29.80 (149 frames in ~5s)
Estimated fps @main=~29.80 (149 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~29.79 (149 frames in ~5s)
Estimated fps @main=~29.79 (149 frames in ~5s)
While this serves as a rough indicator, it effectively fulfills its role in detecting major issues. Suppose a bug is introduced in the face_detector. The log might quickly reveal something unexpected:
Estimated fps @<mbox:type=MPMC:id=12>=~16.79 (84 frames in ~5s)
Estimated fps @main=~30.00 (150 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~17.40 (87 frames in ~5s)
Estimated fps @main=~29.80 (149 frames in ~5s)
Estimated fps @<mbox:type=MPMC:id=12>=~17.60 (88 frames in ~5s)
Estimated fps @main=~30.00 (150 frames in ~5s)
In this case, the two channels have different fps, revealing a slowdown somewhere in the pipeline. This might not be a critical issue, especially if the situation is temporary.
This rough measure lends itself well to integration into an automated test. Frequently, tests of this nature monitor performance trends rather than simply asserting on a singular basis. In essence, we can set up tests to measure the throughput of specific agents or pipelines, like the example above. These tests can then be executed on some selected build agents or dedicated machines – ensuring as much repeatability as possible – that store such metrics and provide access to them. Other scripts can subsequently calculate statistics on the resulting trend over time. This approach extends beyond throughput; it’s a more general technique applicable to many performance indicators that do not demand fine accuracy, conversely, for example, to micro-benchmarking, which needs more sophisticated approaches.
Likewise, it’s possible to create agents that perform such trend analysis in real-time while the system is operational, triggering alerts in the event of issues or unexpected behaviors.
Benchmarking the maximum throughput
fps_estimator and similar agents can be beneficial for checking and monitoring if an up and running system is behaving as expected. However, there are situations where we aim to determine the performance of an agent or a group of agents. For instance, we may want to estimate the maximum throughput of image_resizer, under some conditions.
This value can prove useful for various reasons, such as:
assessing if a particular agent (or group) meets specific performance requirements;
comparing the performance of different agents;
evaluating the impact of using different dispatchers on a specific agent (or group);
conducting benchmarks for specific hardware and platform combinations.
For instance, if the image_resizer is mandated to produce a minimum of 50 fps for a specific use case, the initial assessment would involve determining whether this is feasible at all.
In contrast to the fps_estimator, where the measurement occurs in real-time on an actual or simulated system, in this case, we isolate the calculation within a test bench. The actual calculation closely resembles that performed by the fps_estimator, but in this instance, the quantity of messages to be ingested is predetermined and the system under test is more minimal and is run for a limited amount of time.
The test itself is quite versatile and can be applied for broader purposes beyond the maximum throughput calculation, so we’ll revisit this concept later in the series. First of all, we introduce this support function object:
This class is designed to measure the time it takes to receive a specified number of messages (or signals – here you can see the power of mhood_t in action) on a particular channel. Similar to the fps_estimator, the frequency is determined by dividing the number of messages by the elapsed time. The calculation involves three receiving stages:
when the first message is received, we record the start time;
in the middle stage, we consume all the messages except the last one;
lastly, upon receiving the last expected message, we calculate the frequency.
On the testing side, the setup involves configuring the agents to benchmark. The frequency_calculator can be encapsulated into an async operation. For example:
TEST(performance_tests, image_resizer_maximum_throughput)
{
constexpr unsigned messages_count = 100;
wrapped_env_t sobjectizer;
auto& env = sobjectizer.environment();
auto input_channel = env.create_mbox();
const auto output_channel = create_mchain(env);
env.introduce_coop([&](coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel->as_mbox(), 4.0);
});
auto throughput = async(std::launch::async, frequency_calculator<cv::Mat>{messages_count, output_channel});
const auto test_frame = cv::imread("test_data/replay/1.jpg");
for (auto i = 0u; i<messages_count; ++i)
{
send<cv::Mat>(input_channel, test_frame);
}
cout << format("image_resizer maximum throughput measured on {} frames = {:.2f} fps\n", messages_count, throughput.get());
}
Typically, such tests are not executed only once but multiple times, with the average value being taken as the reference measure. On my machine (Intel i7-11850H @2.50GHz, 8 Cores), the average result from running this test a hundred times is approximately 900 fps.
As mentioned, this test serves as an estimation of the maximum throughput and is not intended as a precise measure, given that the asynchronous operation is not perfectly synchronized with the sending of the images. More sophisticated approaches can be explored for a more accurate assessment. Also, consider these numbers are currently taken on the test image only. To provide a more comprehensive evaluation, a broader range of frame sizes and contents should be considered.
At this point, a possible experiment involves assessing if running image_resizer on multiple threads gives any advantage, since its operation appears to be configurable as thread-safe:
class image_resizer final : public so_5::agent_t
{
public:
// ... as before
void so_define_agent() override
{
so_subscribe(m_input).event([this](const cv::Mat& image) {
cv::Mat resized;
resize(image, resized, {}, m_factor, m_factor);
so_5::send<cv::Mat>(m_output, std::move(resized));
}, so_5::thread_safe);
}
// ... as before
private:
// ... as before
};
To run this experiment, we just need to implement this change and use the adv_thread_pool dispatcher, as learnt in the previous post:
// ... as before
auto pool = so_5::disp::adv_thread_pool::make_dispatcher(sobjectizer.environment(), 2).binder(so_5::disp::adv_thread_pool::bind_params_t{}.fifo(so_5::disp::adv_thread_pool::fifo_t::individual));
env.introduce_coop(pool, [&](coop_t& coop) {
coop.make_agent<image_resizer>(input_channel, output_channel->as_mbox(), 4.0);
});
// ... as before
The results are not impressive, as the throughput of the multi-threaded version is slightly worse than the single-threaded one (around 850 fps). Why is this the case? Further investigation reveals that cv::resize already utilizes multiple threads internally so increasing the contention on the CPU makes things even worse.
A similar single-threaded calculation might be set up for the face_detector:
TEST(performance_tests, face_detector_maximum_throughput)
{
constexpr unsigned messages_count = 100;
wrapped_env_t sobjectizer;
auto& env = sobjectizer.environment();
auto input_channel = env.create_mbox();
const auto output_channel = create_mchain(env);
env.introduce_coop([&](coop_t& coop) {
coop.make_agent<face_detector>(input_channel, output_channel->as_mbox());
});
auto throughput = async(std::launch::async, frequency_calculator<cv::Mat>{messages_count, output_channel});
const auto test_frame = cv::imread("test_data/replay/1.jpg");
for (auto i = 0u; i<messages_count; ++i)
{
send<cv::Mat>(input_channel, test_frame);
}
cout << format("face_detector maximum throughput measured on {} frames = {:.2f} fps\n", messages_count, throughput.get());
}
On my machine, launching this test several times gives, on average, 90 fps.
This approach is primarily effective when observing a channel that is the output of an agent. In essence, if the test is well-isolated, the frames per second (fps) on such a channel will closely align with the throughput of the agent. It’s worth noting that, for even more strict accuracy, the call operator of the frequency_calculator should be synchronized with the sending of data. However, this synchronization overhead is negligible when the cost of each agent’s call is significant.
Takeaway
In this episode we have learned:
performance of actor-based systems are generally characterized by throughput and latency;
throughput is the number of processed messages during a period, usually expressed in a common time unit (e.g. 15 fps);
latency is the duration it takes for a message to be processed from the moment it is sent to the agent’s queue to the moment it’s fully processed;
often, throughput problems are firstly addressed by trying to distribute work (scaling), or by reducing the flow of messages to be processed;
latency is usually more difficult to optimize as it needs further work into the internals of the agents or the design of the system itself;
estimating throughput over time might be convenient to observe if the system is sustainable from a load standpoint;
determining maximum throughput of agents or groups of agents can be done using more isolated tests.
In the next article, our discussion with Helen on performance continues, shifting our focus to another crucial metric within our control: service time.